0x00 Introduction & Background
LSM通常由两部分组件组成:
- 内存组件(Memory Component):主要用来absorb update(在内存组件中absorb update的同时会将数据写入到磁盘日志中,以用于数据恢复);
- 磁盘组件(Disk Component):用于持久化数据,内存组件中的数据超过上限后会flush到磁盘,磁盘组件按照Level的形式进行组织,接近内存组件的Level保存着更新的数据,当某个$L_i$超过上限时会与$L_{i+1}$进行归并压缩,也即在后台执行$Compaction$操作;

$Compaction$和$Flush$是非常关键的操作,负责维护$LSM$的结构和属性,同时这也会占用大量的可用资源。
作者在$Nutanix$的生产环境负载测试中,顶峰时$Compaction$操作对$CPU$的占用率会达到45%。此外,单个集群平均每天要花费两个小时在$Compaction$操作上,以维护元数据存储映射。
文章提出了三种新的互补技术来弥补这些不足。这些技术同时减少了$Compaction$和$Flush$操作所占用的时间和空间资源,并带来了吞吐量的提升。
- 第一项技术减少了倾斜工作负载(skewed workload)下的$Compaction$开销。将频繁更新的$KV$对(也即hot entries)保留在内存组件中,仅对cold entries执行$Flush$操作。这个分离操作减少了hot entry所触发的频繁Compaction操作。
- 第二项技术的主要思想是推迟对文件的Compaction操作,只有当文件的重叠部分足够大时才进行Compaction。
- 第三项技术主要是改变提交日志(commit log)在LSM中的角色,以类似SSTable的形式来使用它们,来避免双写(第一次写到日志,第二次是flush操作所引起的第二次写操作);
0x10 Motivation
尽管I/O操作不在面向用户操作的关键路径中,但是Flush、Compaction、Log等操作仍然会占用大量的计算资源。CPU协调这些操作会占用大量的处理能力,而这些处理能力本来是可以用于为用户提供更好性能体验的。因此I/O操作的频率和长度会对用户感知的最终性能有较大的影响。
为证明I/O操作会导致性能下降,本文设计了相关实验进行验证。选择了两个方面具有负载倾斜的工作负载:
- 数据流行度:skewed和uniform
- 读写混合:write dominated 和 balanced
将上述工作负载运行在普通RocksDB和关闭了后台I/O的RocksDB(例如,可以关闭$Flush$和$Compaction$)中,实验结果绘图如下: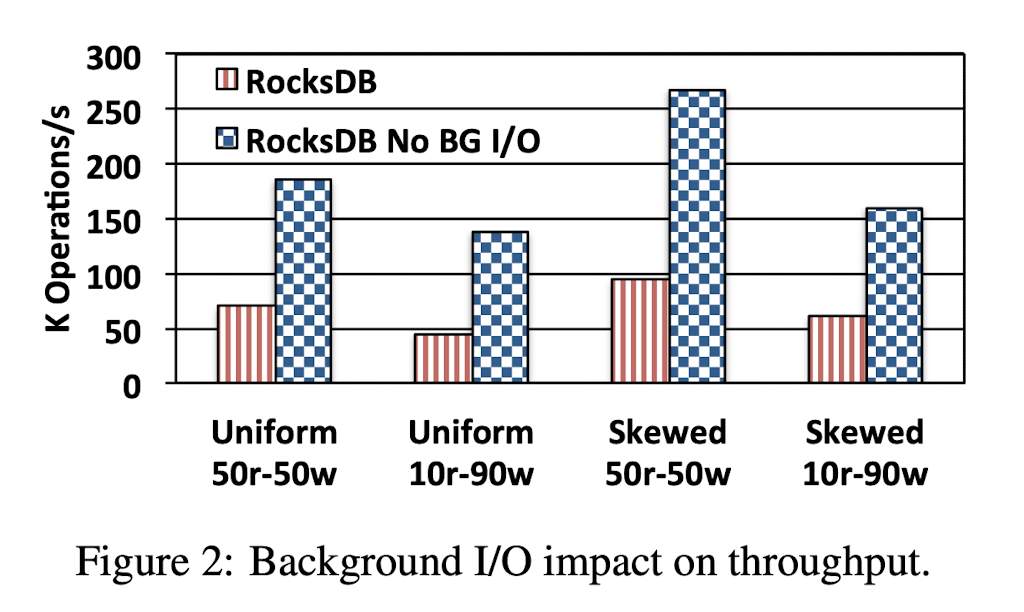
可以看到在各个负载下,关闭了后台I/O的RocksDB都表现出了更优的性能。在此结果的驱动下,本文确定了触发频繁和密集I/O的三个主要原因:
- data-skew unawareness, at the memory component level,也即在内存组件层面上的无意识的数据倾斜(存在冷热键);
- premature and iterative compaction, at the LSM tree level,也即在LSM树层面过早的迭代$Compaction$操作;
- duplicated writes at the logging level,也即在日志层面的双写操作;
0x11 Data skew unawareness (数据倾斜)
很多KV Store的工作负载都表现出数据倾斜的特征,其中hot key的更新频率要远远高于cold key。
数据倾斜导致commit log的增长速度远远大于$C_m$(也即内存中的MemTable和Immutable Memtable)。因为对相同key的更新,日志是以追加的方式存储的,而$C_m$采取的是就地吸收(absorbed in-place)的方式。这会导致$C_m$在达到其上限之前触发$Flush$操作,因为commit log过大会导致在数据恢复时所耗费的时间更长,所以MemTable必须频繁的$Flush$,从而使commit log可以被及时清理掉,通过减小commit log的大小来缩短数据恢复的时间。这不仅会增加$C_m$的$Flush$频率,而且由于其大小是小于其能达到的最大值的,导致$L_0$中打开和存储文件的固定成本并没有被实际写入数据更好的摊分。
0x12 Premature and iterative compaction (过早Compaction)
现有的基于LSM的KV-Store在Compaction过程中表现出了两方面的限制。
一些KV-store在$L_0$中仅保留一个SSTable,以加快读速率。但这样会导致每次内存组件的Flush操作都会触发一次$L_0$和底层Level的Compaction操作,也即导致了频繁的Compaction操作。这便是第一种限制。
另外一些LSM的方案是在$L_0$保存多个SSTable,这会导致第二种限制。主要表现在,当$L_0$中有多个SSTable时,LSM如何将$L_0$ Compaction到$L_1$。事实上,$L_0$中的多个文件是一次性Compaction到更高的Level的,这从而也会导致多个连续的Compaction操作。也即如果$L_0$中的两个SSTable都有一个相同的key,那么这个key将会在底层的LSM树中执行两次Compaction操作。而数据倾斜会加剧这个问题,因为它增加了$L_0$中多个SSTable拥有共同key的概率。显然,当系统的负载越高时,这种事件发生的概率也会越高。
0x13 Duplicate writes(双写)
当$C_m$被Flush到$L_0$中后,相应的commit log便会被删除掉,因为$Flush$操作已经能够保证数据的持久化。Flush到$L_0$的每个KV对都是最新的版本,都对应了一个commit log,因此$Flush$操作不过是重放了在追加commit log时已经执行过的I/O操作。
0x20 Technique——TRIAD
文章用来解决I/O开销的方法体现在三个方面,每个解决方案都对应了前面提到的一个挑战:
- TRIAD-MEM 通过冷热键分离来解决内存组件中的data skew问题;
- TRIAD- DISK 通过推迟和批量Compaction来解决磁盘组件中的premature and iterative compaction问题;
- TRIAD- LOG 通过绕过$Flush$过程中创建新SSTable来解决日志层面中的duplicate write问题;
0x21 TRIAD-MEM
TRIAD-MEM的目标是利用大多数工作负载所表现出的数据倾斜的特点来减少Flush,并进一步减少Compaction的频率。为了做到这一点,TRIAD-MEM仅将cold key flush到磁盘上,而将hot key保留在内存中(但也要写commit log)。这能避免触发大量的Compaction操作,从而降低磁盘中重叠Key的数量。
将hot key保留在内存中,便可以在内存中完成更新操作,这可以避免在磁盘上触发大量的Compaction操作。
图3展示了Flush期间冷热键分离的过程,图4展示了Flush完成后的状态。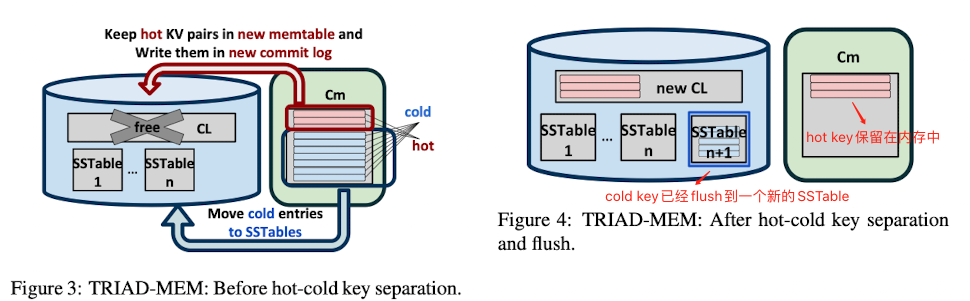
算法2展示了冷热键是如何分离的。旧$C_m$中的前K个条目被选中,其中K是系统的参数。理想情况下,K的取值应该既能保存尽量多的hot key,还能避免引起较高的内存开销。
保留在内存中的hot key 不需要Flush到磁盘上,但在更新时仍然需要写commit log(如图3所示),以保证在宕机时能完成数据恢复。
当$C_m$的大小不超过某个阈值(算法1中的FLUSH_TH)时,分离冷热键时不会进行$Flush$。因为在工作负载不均衡时,$Flush$ 可能是因为commit log满了而不是$C_m$满了所触发的(commit log太多会造成数据恢复时间过长,所以commit log过多时也会触发$Flush$)。所以,为了避免$Flush$小的$C_m$文件,算法会将所有条目都保存在内存中,并根据这些条目创建新的commit log,丢弃旧的commit log。
0x22 TRIAD-DISK
TRIAD-DISK会推迟Compaction操作,直到需要Compaction的文件有足够多的key重叠。为了估计文件之间的key重叠,文章使用了HyperLogLog (HLL)概率基数估计器。
为了计算一组文件之间的重叠,文章定义了一个重叠率(overlap ratio),假设在$L_0$中有$n$个文件,则重叠率可以定义为:
$$
1-\frac{ UniqueKeys(file_1, file_2,… ,file_n)}{sum(Keys(file_i))}
$$
其中:
- $Keys(file_i)$表示第$i$个SSTable中的key数量;
- $UniqueKeys(file_1, file_2,… ,file_n))$表示合并$n$个文件后的唯一key的数量;
图5展示了overlap ratio 是如何来推迟Compaction的。
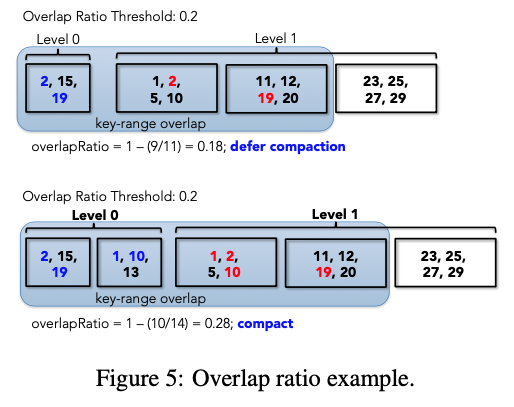
在$L_0$中执行每次Compaction之前,我们会先计算出$L_0$中所有文件的overlap ratio,如果overlap ratio小于阈值,则推迟Compaction(除非$L_0$中文件的数量超过允许的最大值,如果超过,那么不再考虑overlap ratio,强制允许Compaction)。
0x23 TRIAD-LOG
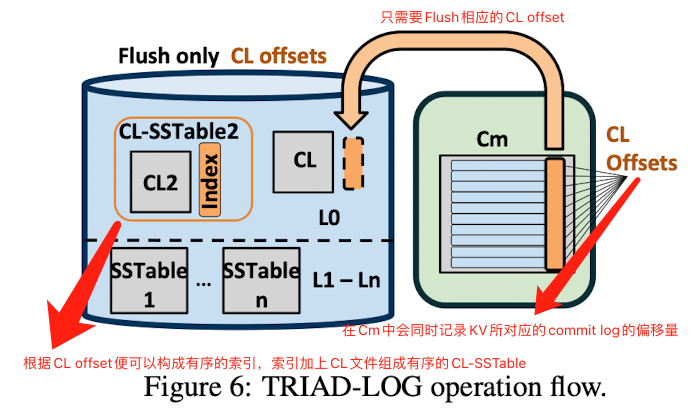
TRIAD-LOG的主要思路是,内存中需要Flush到磁盘中的数据已经在Commit Log(CL)中了,可以对Commit Log进行利用而不必通过Flush操作再重写一次。主要思想就是将CL转为$L_0$中一种特殊的SSTable,也即CL-SSTable,这种方式可以避免完整的Flush操作。
TRIAD-LOG增强了Commit Log角色的能力。当向$C_m$写入数据时,commit log就扮演其普通WAL的角色。当触发Flush操作时,将commit log转为CL-SSTable而不是将$C_m$重写到$L_0$。
将commit log作为$L_0$中的SSTable可以避免Flush操作所带来的I/O开销,但SSTable是有序的,而commit log是追加生成的、是无序的。SSTable有序的特性可以加速Compaction操作和检索操作。
为了避免在$L_0$中查找某个条目时需要扫描整个CL-SSTable,TRIAD-LOG在$C_m$中保存每个KV对应的最近更新的commit log文件的偏移量,以帮助构建有序的CL-SSTable。一旦Flush操作被触发,只需要将与最新的commit log偏移量相关联的索引写到磁盘上(索引也即index的大小与整个KV相比是很小的,所以仅刷新index的开销很小,文章并没有对index有明确说明,我觉的这里的index可以是(key, CL name, offset)的组合,通过这个index再加上CL就可以组成有序的CL-SSTable了)。
TRIAD-LOG并没有改变写操作的流程,不同之处仅在于,在$C_m$中执行更新时会把对应的commit log的偏移量和文件名也写入到$C_m$中(例如,(key, value, offset, CL name))。其流程如下图所示: