
0x00 Introduction
LSM树在内存中缓存数据的更新,并周期性的将它们刷新到磁盘上,生成不可变的table文件,完成数据持久化。但是这也降低了查询效率,因为一个range中的key可能在不同的table文件中,并且由于较高的计算和I/O成本,这可能会潜在的降低查询速度。
学术界针对此问题已经做了大量工作来加快查询性能。为了加快点查询,每个table文件通常都与内存中的一个布隆过滤器相关联,以此来跳过不含目标key的table文件。但是布隆过滤器不能处理范围查询。
为了限制查询请求不得不访问的table数量,LSM树会在后台运行一个Compaction线程来不断对table进行归并排序。其中table的选择由Compaction策略来决定。
Leveled Compaction
Leveled Compaction策略被包括LevelDB和RocksDB在内的大量KV-Store使用。Leveled Compaction将多个较小的有序run归并排序为一个较大的有序run,以保证存在重叠的table文件数量小于指定的阈值。Leveled Compaction通过如上策略提供了较高的读效率,但因为其密集的归并排序策略,这也带来了比较高的「写放大」(Write Amplification,WA)。
Tiered Compaction
Tiered Compaction压缩策略等待多个大小相似的有序run,将它们合并为一个更大的run。其提供了更低的WA和更高的吞吐量,被Cassandra和ScyllaDB等KV-Store使用。但是Tiered Compaction不能有效降低存在key重叠的table数量,与Leveled Compaction相比这会带来更高的查询成本。
Problem
其他的一些压缩策略虽然能比较好的平衡读写性能,但都没能同时实现高效的读写性能。
主要问题在于,为了限制有序run的数量,KV-Store必须进行归并排序和重写数据。现在的存储技术已经大大提高了随机读的性能。例如,对于Flash SSD来说,随机读的速度能达到顺序读速度的50%。例如3D-XPoint等新技术,为随机读和顺序读提供了几乎相同的性能。因此,KV-pairs不需要为了快速访问而进行物理排序;相反,KV-Store可以通过逻辑排序来提供高效的点查询和范围查询,以避免大量的重写操作。
为此,本文设计了REMIX(Range-query-Efficient Multi-table Index)。传统的解决方案为了提高range query效率而在物理数据重写和昂贵的归并排序之间挣扎,而REMIX利用了节省空间的数据结构来记录跨多个table文件的全局排序视图。通过使用REMIXes,LSM-KVS可以在不牺牲查询性能的前提下,使用具有高写效率的压缩策略。
0x10 Background
LSM树是为了在持久化存储设备上实现高效的写速率而设计的。它将所有的更新缓存在内存中一个称为MemTable的数据结构中,以此来实现高效的写性能。
- minor compaction:当MemTable写满后,LSM树会通过minor compaction操作将缓存的所有key进行排序,并将其作为一个run刷新(flush)到持久化的存储设备上。此操作不需要对存储设备上的现有数据进行合并,只需要批量顺序写入,因此实现了高效写性能;
- major compaction:有序的run之间可能会存在重叠的key范围,这时一个点查询(point query)就不得不去检查所有可能的run,这带来了较大的查询开销。为了限制存在重叠的run的数量,LSM树通过major compaction操作将几个存在重叠的run归并排序为一个run。
压缩策略(compaction strategy)决定了如何选择table进行major compaction。最流行的两种压缩策略是leveled compaction和tiered compaction:
leveled compaction :
使用此方法的数据库具有多层的结构,每层都维持一个由一个或多个table组成的有序run。其中某一个Level $L_n$的容量是其前一个Level $L_{n-1}$的几倍(通常是10),这使得一个庞大的KV-store被组织为仅有几个Level组成(通常是5~7个)。Leveled Compaction带来了相对高效的读性能,但也会造成写性能较差。Leveled Compaction从相邻的Level(例如$L_n$和$L_{n+1}$)中选择重叠的table进行合并,并在较大的Level(例如$L_{n+1}$)中生成新的table。因为不同Level之间的容量呈指数级增长,因此一个table的键范围通常与下一个Level的多个table重叠。因此大多数写操作是在$L_{n+1}$中重写已有的数据,这在实践中导致了高达40倍的高「写放大比」(write amplification ratio, WA ratio,即实际写入磁盘的数据量与用户请求写入的数据量的比值)。
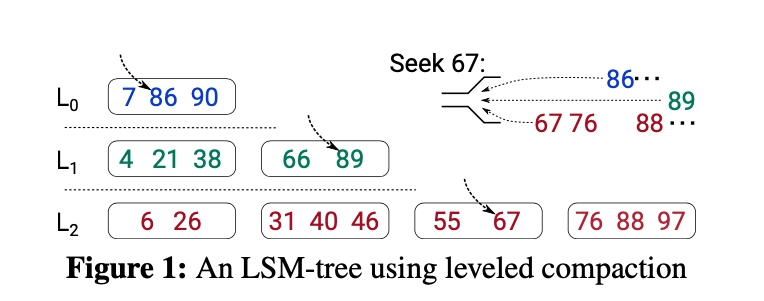
图1展示了一个Leveled Compaction的例子,每个table包含1~2个key。如果$L_1$中的第一个table被选择与$L_2$中的前两个table进行归并排序,那么$L_2$中的5个key将被重写(也即table(4,21,38)要与table(6,26)和table(31,40,46)进行归并排序,此时$L_2$两个table中的5个key都需要重写)。
tired compaction:
如图2所示,在使用tired compaction的LSM树中,在一个level中可以缓存多个存在重叠的有序run。通常,一个level中run的数量会通过一个阈值$T$来限制($T>1$)。如果在一个level(例如$L_n$)中的有序run的数量超过阈值$T$,那么**$L_n$中的所有run会被归并排序为$L_{n+1}$中的一个新的run,$L_{n+1}$中的数据不会被重写**。因此,在使用tired compaction的LSM树中,写放大比为$O(L)$,其中$L$是level的数量。但是,由于在每个level中可能会有多个重叠的有序run,一个点查询(point query)可能会需要去检查$T\times L$个table,这也导致了更低的查询性能。

LevelDB和RocksDB中的范围查询是通过使用一个迭代器结构在多个table中导航实现的,就好像所有的key都在一个有序run中。一个范围查询首先会使用带有搜索键(seek key,也即目标key范围的下边界)的搜索操作(seek operation)来初始化迭代器。「查找操作」首先定位迭代器,使其指向存储中大于等于seek key的最小key,这表示范围查询的目标key。next操作会往前推进迭代器,使其指向有序run中的下一个key。因此,可以使用一系列next操作来检索目标范围内的key,直到满足某个条件(例如达到查询的数量或者到达查询范围的末尾)。由于有序run是按时间顺序生成的,因此一个目标key可能会在任何一个run中,相应的,迭代器必须追踪所有的有序run。
图1展示了一个使用leveled compaction的LSM树的查找示例。为了查找key 67,需要在每个run中使用二分查找来识别满足$key \geq seek,key$的最小key。每个识别的key都用一个光标(cursor)来标记。然后使用最小堆结果来对这些键进行归并排序,从而选择$L_2$中的key 67。随后,每个next操作都会比较光标标记下的key,返回其中最小的一个key,然后向前移动其对应的光标。如图1右上角所示,此过程会呈现key的全局排序视图。在图1的例子中,所有的3个level都会被访问以进行归并排序。图2使用的是tired compaction,但查询过程类似,不过在这个例子中有6个run需要被访问,其查找代价相对更大。
0x20 REMIX
对多个有序run的范围查询会动态构建底层table的排序视图,以便可以按照排序顺序来检索key。事实上,排序视图继承了table文件的不变性,并会在任何table被删除或替代前保持有效。然而现有的基于LSM的KV-Store并没有利用这种不变性的特点,排序视图会在查询时反复重建和丢弃,这会带来密集的计算和I/O操作并导致较差的查找性能。
REMIX的动机是利用table文件的不变性,保留底层table文件的排序视图,以在将来的查询操作中重用它们。
如果记录每个key及其位置来保留排序视图,则存储的元数据可能会显著膨胀,从而导致读写性能受损。因此,为了避免这个问题,REMIX的数据结构必须是空间高效的。
0x21 The REMIX Data Structure
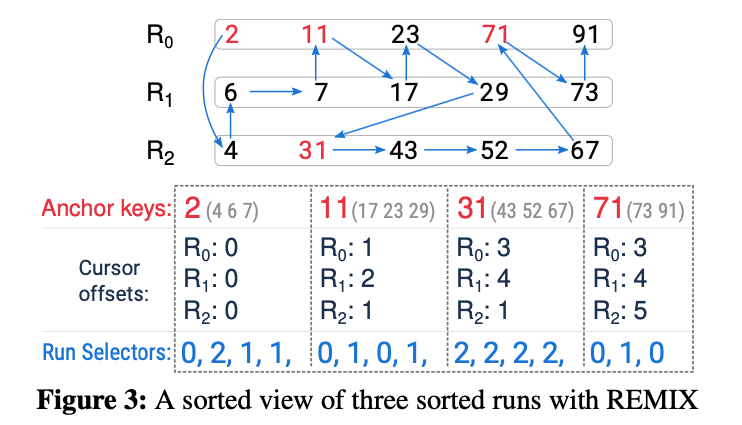
图3上部展示了一个由三个run组成的排序视图的示例,排序视图用向量将15个key连接起来。
为了构建一个REMIX,首先将排序视图的key划分到多个segment中,每个segment都包含固定数量的key。
每个segment都与一个anchor key,一组cursor offset以及一组run selectors关联。其中:
- anchor key:表示segment中的最小key;
- cursors offsets:所有cursor共同组成了排序视图上的稀疏索引,每个cursor offset都与一个run对应,并记录了此run中大于等于anchor key的最小key;
- run selectors:segment中的每个key都有一个对应的run selector,run selector用来指示对应的key位于哪个run上;
REMIX的迭代器不使用最小堆。在REMIX中,一个迭代器包含「一组cursor」和「一个current pointer」。
- cursors:每个cursor都与一个run相关联,并指向该run中一个key的位置。
- current pointer:选择并指向一个run selector,该run的cursor决定了此时到达的key;
在REMIX中,使用一个迭代器来查找一个key需要三步:
- 找到target segment。在anchor keys上执行二分查找,以确定包含seek key的target segment,也即找到满足anchor_key$\leq$seek_key的segment;
- 初始化迭代器。将迭代器初始化为指向anchor key。具体来说就是,用target segment的cursor offsets来初始化迭代器的cursors,并将迭代器的current pointer指向target segment的第一个run selector;
- 可以通过线性扫描有序视图来查找 target key。为了移动迭代器,将当前key的cursor前进以跳过当前key,同时,current pointer也需要前进以指向下一个run selector;
来看一个例子。如图3所示,底部的四个方框代表编码了有序视图的REMIX元数据(需要注意的是括号中的key并不是元数据的一部分)。查找key 17的操作如下:
- 查找target segment。通过二分查找,第二个segment被选中,其包含的key为
(11,17,23,29)。 - 初始化迭代器。根据target segment的cursors offset,也即
(1,2,1),将迭代器的cursors放在$R_0$、$R_1$和$R_2$的键11、17和31上;与此同时,将迭代器的current pointer设置为指向target segment的第一个run selector(图中的第5个run selector,也就是第二个segment的第一个run selector,为0,指向的是第一个run),这意味着current key也即key 11在$R_0$的cursor所在的位置。 - current key 11小于17,迭代器需要向前移动,以查找下一个满足$k\geq17$的最小key。为了向前移动迭代器,$R_0$的cursor向前移动跳过key 11,停在key 23上,此时迭代器的cursors offset为
(2,2,2);然后current pointer向前移动到target segment的第二个run selector(图中的第6个run selector,也就是第二个segment的第二个run selector,为1,指向的是第二个run)。重复此操作最终找到目标key。
0x22 Efficient Search in a Segment
seek操作通过在anchor keys上执行二分查找来定位target segment以初始化迭代器,然后再在有序视图上向前扫描来查找target key。显然,增加segment的大小能减少anchor key的数量,并进一步加速二分查找。但这也会降低查找target key的速度,因为需要在一个更大的target segment上访问更多的key来查找target key。
为了解决潜在的性能问题,REMIX在target segment中也使用二分查找来最小化查找开销。
目前为止,使用二分查找的地方有:
- anchor keys之间:在anchor keys上执行二分查找来定位target segment;
- target segment内部:在target segment上执行二分查找来定位target key;
但是,要在segment上使用二分查找则必须能随机访问segment中的每个key。
由上文可知,segment中的每个key属于一个run,并用run selector指示其所在的run。为了访问一个key,我们需要将run的cursor放在正确的位置上,可以通过计算在「该key之前」并「与其相同的run selector的出现次数」,然后将cursor移动相应的次数来将cursor放置到正确的位置上。通过这种类似数组的访问模式,我们可以实现segment中每个key的随机访问。
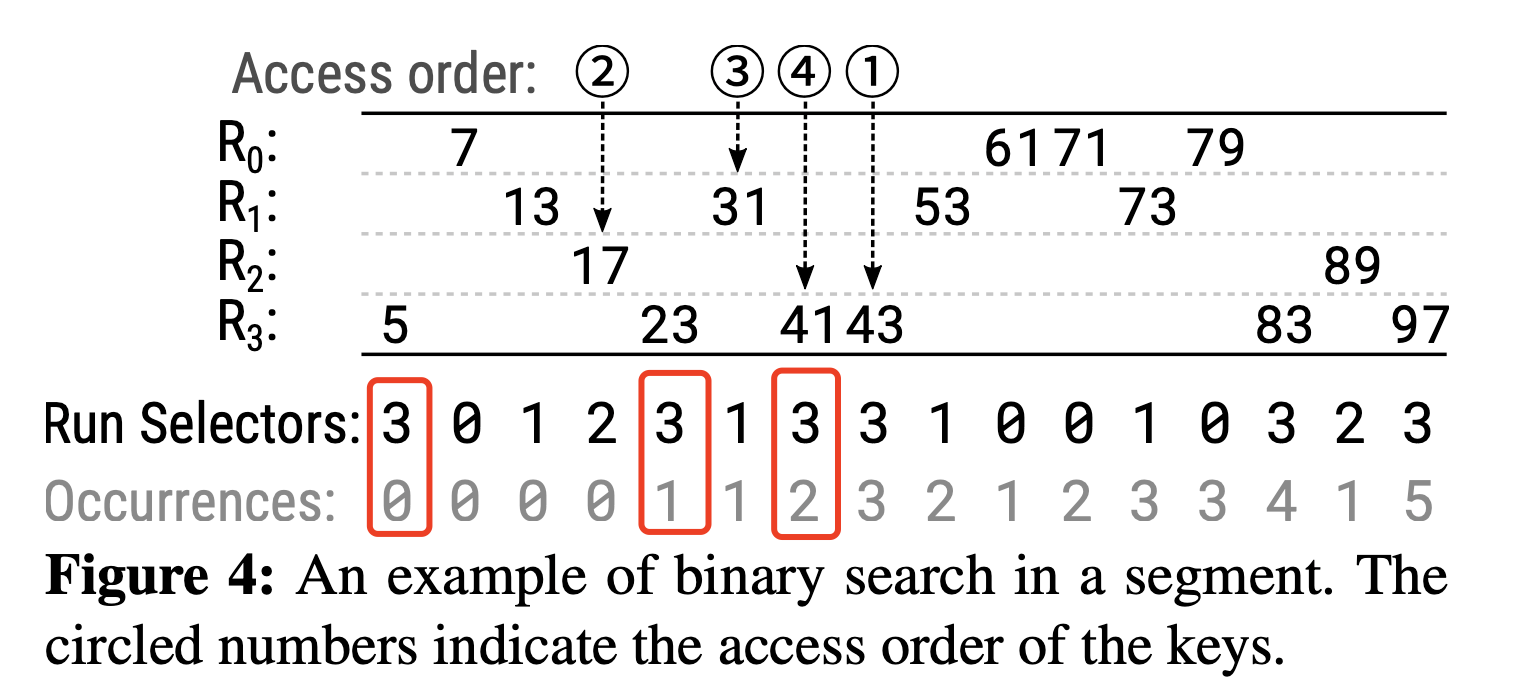
图4展示了一个有16个key的segment,所有的key位于不同的4个run上。Run Selectors下面的Occurrences表示该segment中某个key之前还有多少个key与它位于同一个run中。例如,key 41是该segment中位于$R_3$上的第3个key,也即在key 41之前还有2个key位于$R_3$上(key 5和key 23),所以其Occurrences值为2。要查找访问 key 41,我们只需要初始化$R_3$的cursor offset,然后向前移动两次跳过key 5和key 23即可,这便实现了key 41的随机访问。
简单记录一个segment中二分查找的过程,还是例如要查找key 41,过程如下:
- 第一次执行二分查找。需要检索的是该segment中的第8个key(总共16个key,所以第一次检索第8个key),该key对应的run selector为3,occurrence值为3,然后初始化$R_3$的cursor offset,然后向前移动3次即可访问该key,该key为43。该key不是我们要找的key 41,且大于key 41;
- 第二次执行二分查找。由第一次可知,需要在segment中的第1~7个key进行二分查找,因此第二次二分查找需要检索第4个key,该key对应的run selector为2,occurrence为0,初始化$R_2$的cursor offset,向前移动0次即可访问该key,该key为31,仍不是要查找的key。
- 第三次执行二分查找。方法同上,本次检索第6个key,仍不是要查找的key。
- 第四次执行二分查找。方法同上,本次检索第7个key,是本次查找的target key,查找结束。
在segment中使用二分查找可以减少查找过程中key比较的次数,但是,查找路径中的key可能位于不同的run上,而若相应的block没有被缓存的话则必须通过独立的I/O请求来读取这些key。例如,我们上面的查找例子中,只需要进行4次二分查找也即需要比较4次,但是需要访问3个run(4次比较中的key位于3个不同的run上)。事实上,很有可能该segment中位于同一个run上的几个key可能在同一个block中,因此,在一次比较完成后,移动到下一个run之前,可以通过比较该run上位于同一个block中的key来进一步缩小查找区间。例如,假设$R_3$中的key 41和key 43位于同一个block中,且我们要查找的target key也是key 43,则第一次需要检索key 41进行比较,比较完成后,在移动到$R_0$上访问Key 71比较之前,可以顺便比较一下与它位于同一block中的key 43,而这个key正好是我们需要的target key,此次访问直接将查找区间缩小到了target key。
0x23 Search Efficiency
REMIX在以下三个方面改进了范围查询:
- REMIX使用二分查找来定位target key。REMIX提供了一个由多个run组成的全局视图,只需要一个二分查找就可以在该全局视图中定位到target key。
- REMIX移动迭代器时不需要key的比较。REMIX通过使用预先记录的run selector来更新迭代器的cursors和current pointer,可以直接切换到下一个KV对。此过程不需要任何的key比较。相比之下,传统LSM-KVS的迭代器会维护一个最小堆,以对来自多个重叠run的key进行归并排序,在这种情况下,一个next操作需要从多个run中读取key进行比较。
- REMIX会跳过不在查找路径中的run。seek操作会在target segment中执行二分查找,而且在查询时仅会访问那些包含查找路径上的key的run。
此外,显著降低的查询成本允许在不使用布隆过滤器的情况下对由REMIX索引的多个有序run进行高效的点查询。
0x24 REMIX Storage Cost
REMIX的元数据由三个组件组成:anchor keys、cursor offsets、run selectors。为了对其存储成本进行评估,现给出如下定义:
- $D$表示一个segment中最多能包含的key的数量,因为每个key都有一个对应的run selector,那么run selector的数量相应的也为D;
- $S$表示cursor offset的大小,单位为字节;
- $H$表示被REMIX索引的run的数量;
- $\bar{L}$表示anchor key的平均大小,单位为字节;
由上面的定义可得:
- $S \times H$ 表示一个segment中所有的cursor offset所占用的空间大小,单位为字节;
- $\left \lceil log_2(H) \right \rceil/8$ 表示一个run selector所占用的空间大小,单位为字节;
- $D \times \left \lceil log_2(H) \right \rceil/8$ 表示一个segment中所有run selector所占用的空间大小,单位为字节;
那么由上面的定义和推理可得,REMIX中各个组件占用的空间大小为(单位为字节):
- anchor keys :$\bar{L}$个字节;
- cursor offsets:$SH$个字节;
- run selectors:$D \times \left \lceil log_2(H) \right \rceil/8$个字节
将REMIX所占用的总空间大小摊分到每个key上(也即将占用总空间大小除D),则每个key所额外占用的空间大小为:
$$
(\bar{L}+SH)/D + \left \lceil log_2(H) \right \rceil/8
$$
表1展示了在不同工作负载($D$,也即segment中的key数量不同)下的REMIX空间开销。

0x30 RemixDB
为了评估REMIX的性能,本文设计实现了一个名为RemixDB的LSM-KVS。RemixDB为了实现最好的的读性能而采用了tiered compaction。现实世界中的工作负载通常表现出高空间局部性。最近的研究表明,分区存储布局可以有效降低实际工作负载下的压缩成本。RemixDB采用了这种方法,将key空间划分到多个不重叠的分区中。每个分区中的table文件由一个REMIX进行索引,以提供分区的排序视图。通过这种方式,RemixDB本质上是一个使用tiered compaction的单层LSM树。RemixDB不仅继承了tiered compaction的写效率,而且在REMIXes的帮助下实现了高效读性能。
图5显示了RemixDB的系统组件。分区中的压缩会创建一个新版本的分区,其中包含新旧table文件和新的REMIX文件,旧版本在压缩后会被垃圾回收。

在多层LSM树的设计中,一个MemTable的大小通常只有几十MB,接近SSTable的默认大小。而在分区存储布局中,更大的MemTable可以在触发压缩前吸收更多的更新,这能帮助降低WA(写放大,Write Amplification),且MemTable和WAL的空间成本几乎不变,考虑到现在数据中心的大内存和存储,这是适中的。在RemixDB中,MemTable的最大大小被设置为4GB。
0x31 The Structures of RemixDB Files
Table Files
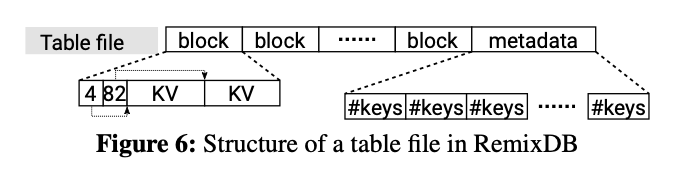
图6显示了RemixDB中的table文件格式。
- data block的默认大小为4Kb;
- 无法存放在一个data block中的大KV对会存放在整数倍的data block中;
- 每个data block在其首部都有一个记录KV数据偏移量的数组,以随机访问它所存储的每个KV数据;
- metadata block是由多个8-bit值所组成的数组,每个值记录了一个4KB的block中所存储的key的数量,因此一个block最多可以存储255个KV对;
REMIX Files
图7显示了RemixDB中的REMIX文件格式。
REMIX中的anchor keys被组织在一个类似B+树的不可变索引中,这有助于对anchor key进行二分查找。每个anchor key都与一个segment ID相关联,segment ID标识了该segment的cursor offsets和run selectors。cursor offset由16位的block index和8位的key index索引组成,如图7的blk-id和key-id所示。因为每个cursor offset都与一个run对应,所以图7中的每个segment的查找路径中都只有两个run。
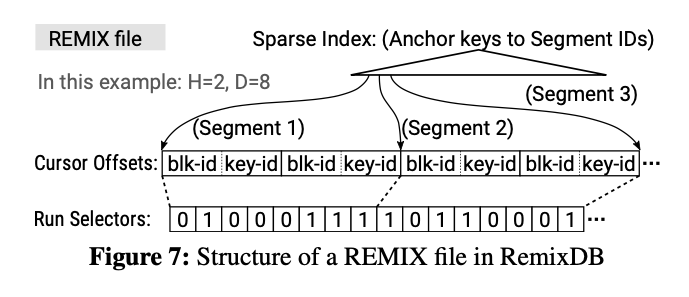
一个key的多个版本可能存在于同一个分区的不同table文件中,范围查询必须跳过旧版本返回每个key的最新版本。因此,在REMIX中,一个key的多个版本在排序视图上从最新到最旧排序,并且每个run selector的最高位被保留以用来区分旧版本和新版本。在前向扫描过程中总是先遇到最新版本,通过检查run selector的最高位可以在不进行比较的情况下跳过旧版本。
0x32 Compaction
在每个分区中,压缩进程根据进入分区的「新数据的大小」和「现有table文件的布局」来估计压缩成本,然后根据该成本执行以下不同的操作:
- Abort:取消分区的压缩,并将新数据保留在MemTable和WAL中;
- Minor Compaction:将新数据写入到一个或多个新的table中,而不重写现有的table文件;
- Major Compaction:将新数据与部分或全部现有table文件合并;
- Split Compaction:将新数据与所有现有数据合并,并将分区拆分为几个新分区;
Abort
compaction后,任何看到新table文件的分区都需要重建其REMIX。Minor Compaction后会在一个分区中创建一个小的table文件,这会导致REMIX的重建并带来高I/O开销。
为了减少I/O开销,如果预估的I/O开销大于阈值,RemixDB可以终止分区的压缩。在这种情况下新的KV数据会被继续保留在MemTable和WAL中,等待下一次压缩。
但是在极端的情况下,当RemixDB终止了大多数分区的压缩时,压缩过程将无法有效的将数据移动到分区中。为了避免这个问题,RemixDB进一步限制可以留在MemTable和WAL中的新数据的大小,如果超过MemTable大小的15%。因此,在达到此限制之前,RemixDB终止具有高I/O开销的压缩过程,达到上限之后不再继续终止,允许压缩。
Minor Compaction
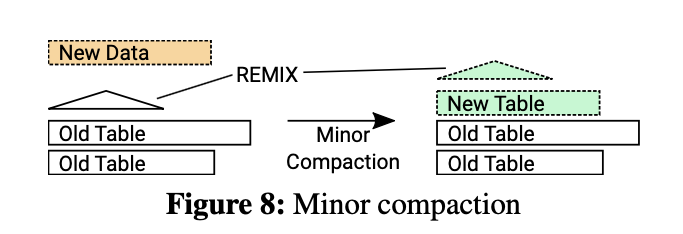
Minor Compaction将Immutable MemTable中的新KV数据写到分区的新table文件中,然后重建REMIX,这个过程不需要重写分区中现有的table文件。当压缩后的Table文件的数量(现有table加上新建table的数量)低于阈值T时,使用Minor Compaction,在RemixDB的实现中T为10。图8显示了一个minor compaction的例子。
Major Compaction
当分区中的table文件的预期数量超过阈值T时,进行Major Compaction,将现有的table文件归并排序为较少的table文件。随着table文件数量的减少,后面就可以执行minor compaction。Major Compaction的效率可以通过输入table文件的数量和输出table文件的数量之比来估计。
图9显示了一个Major Compaction的示例,新数据与现有的三个较小的table文件进行合并,合并后只创建了一个新的table文件,此时$ratio=3/1$。Major Compaction会选择可以产生最高输入输出比的方案进行压缩。

Split Compaction
当分区中充满了large table时,Major Compaction可能无法有效减少分区中的table数量,这可以通过较低的输入输出比来预测。在这种情况下,应该将分区拆分为多个分区,这样每个分区中的table文件数量都能大大减少。Split Compaction会将新数据与分区中的所有现有table文件进行合并,并生成新的table文件以形成多个新分区。图10显示了一个split compaction的例子。

0x33 Rebuilding REMIXes
在具有高空间局部性的现实世界工作负载下,分区存储布局可以有效的最小化压缩成本。具体来说,RemixDB可以在少数分区中吸收大部分更新,并且可以避免接受具有较少更新的分区中的压缩。但是,如果工作负载缺少空间局部性,则不可避免的会有大量分区在较少更新的情况下执行压缩。Tiered Compaction可以最大限度的减少这些分区中的写入,但是在分区中重建REMIX仍然需要读取现有的table。
在分区中重建REMIX时,现有table已经被现有的REMIX索引,并且可以将这些table视为一个有序run,因此,重建过程相当于对两个已排序的run进行归并排序,其中一个来自现有数据,另一个来自新数据。