
0x10 Background
在键值数据库中,Bloom Filter通常用来减少读操作中的I/O次数。在LevelDB中,每个SSTable都有一个关联的Bloom Filter。
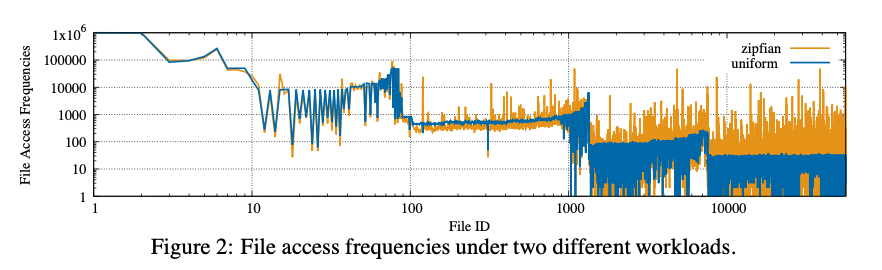
图2展示了两种不同的工作负载下的文件访问频率。
可以看到,随着Level的增加,文件的访问频率在降低,因为越高的Level拥有越多的SSTable,访问的SSTable也会增加。
因此,lower level的SSTable相比heigher level的SSTable需要更低的误报率(False Positive Rate,FPR)。
Monkey通过在lower level上为每个Bloom Filter增加更多的bits-per-key来最大化均匀数据分布下的读操作吞吐量。但是,该论文指出,即使是在同一Level中,SSTable的访问频率不一致也是非常普遍的,显然Monkey并没有考虑这种同一Level中的数据访问倾斜。
因此,从访问局部性的角度来看,为同一Level中不同SSTable的Bloom Filter分配相同的bits-per-key显然不是有效的做法。
所以,对Hot-SSTable的Bloom Filter分配更多的bits-per-key,并对Cold-SSTable的Bloom Filter减少bits-per-key,可以在占用相同内存空间的情况下减少FPR。
0x20 ElasticBF
0x21 Main Idea
Hot-SSTable的数量要远小于Cold-SSTable的数量,因此,可以通过增加Hot-SSTable对应的BF的bits-per-key来减少FP,进而减少由于FP所带来的额外I/O数。
同时,还可以通过减少Cold-SSTable的BF的bits-per-key来控制整体BF所占用的内存空间。
问题在于,为每个Filter所分配的bits-per-key是固定大小的,且一旦生成Filter便无法再对其进行调整。因此,无法在运行时态去动态调整Filter的bits-per-key。
为了解决以上问题,该论文选择在构建每个SSTable时为其分配多个Filter,每个Filter为其分配较少的bits-per-key,将其称为Filter Unit。可以通过使一些Filter Unit生效并将其加载到内存中,或关闭部分Filter unit并将其移出内存,来动态调整每个SSTable的Filter数量(也可以说成调整Filter大小)。
通过这种方法,能够弹性的去动态调整bits-per-key或着说是FPR,该论文将该实现称为ElasticBF。
在ElasticBF中,每个SSTable在初始化是为其分配多个Filter Unit,每个Filter Unit采用不同的哈希函数,Filter Unit按顺序放在SSTable的元数据区域。一个SSTable的所有Filter Unit合称为一个Filter Group。
ElasticBF的结构如图3所示。
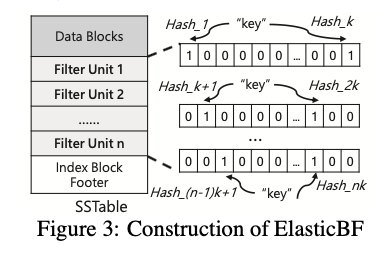
因为在一个Filter Group中的所有Filter Unit是相互独立的,因此在查询key时,只要有一个Filter Unit指示不存在此key,便能确定所属SSTable不含此key。只有当所有的Filter Unit都指示可能包含时才会进一步查询。
假设每个Filter Unit是一个具有b/n bits-per-key的过滤器,所以他的FPR可以表示为$0.618^{b/n}$ ,又因为各个Filter Unit是相互独立的,所以一个具有n个Filter Unit的Filter Group的FPR为$(0.618^{b/n})^n = 0.618^b$。
所以,我们可以得出结论,一个总共具有b bits-per-key的Filter Group与具有b bits-per-key的单个Filter Bloom有相同的FPR。
将ElasticBF部署在KV Store 中主要有两个挑战:
- 如何设计一个调整规则来为每个SSTable选择合适的Filter Unit数量;
- 如何以较小的开销实现动态调整;
0x22 Adjusting Rule
为SSTable调整Bloom Filter的目标是减少FP(False Positive)所带来的额外I/O开销。因此该论文文使用一个Metric来指导调整Filter Unit,该Metric被定义为FP所带来的预计I/O次数,也即E[Extra_IO],具体可表示为:
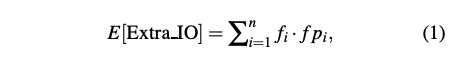
- n 表示KV Store中的SSTable总数量;
- $f_i$表示SSTable i的访问频率;
- $fp_i$表示FPR,它由SSTable i被加载到内存中的Filter Unit的数量所决定;
ElasticBF仅当在不多占用内存空间且可以减少E[Extra_IO]时才会去为每个SSTable调整其Filter Unit数量。
在使用相同大小的Bloom Filter时,访问频率较高的SSTable贡献了更多的E[Extra_IO]。因此在固定内存空间大小的情况下减少E[Extra_IO]就需要为Hot-SSTable分配更多的Filter Unit。
调整BF的步骤如下:
- 当一个SSTable被访问时,将他的访问频率加1,并更新E[Extra_IO];
- 检查是否可以通过enable此SSTable的Filter Unit数量,并disable其他SSTable同等数量Filter Unit的前提下减少E[Extra_IO],也即在不增加内存空间的情况下通过合理调整不同SSTable的Filter Unit数量来减少I/O开销;
然而这又带来了新的问题,也即如何在不增加开销的情况下快速寻找哪些Filter Unit可以被disable。
0x23 Dynamic Adjustment with MQ
如图4所示,该论文维护了多个LRU(Least-Recently-Used)队列来管理每个SSTable的元数据,这些队列被依次命名为$Q_0,…, Q_m$,m是SSTable被分配的Filter Unit数量上限。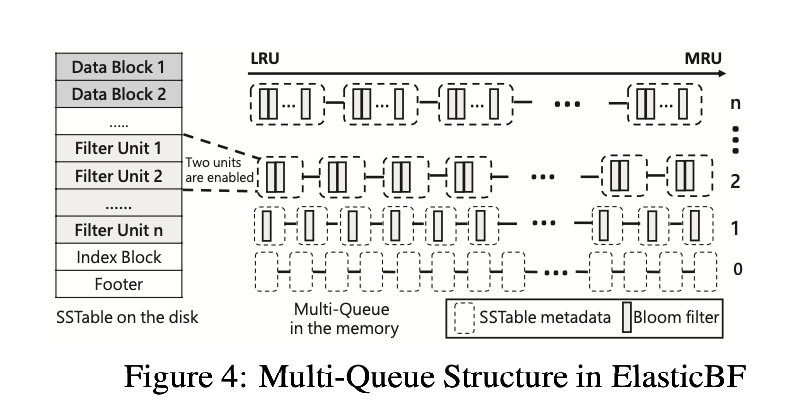
需要注意的是,Filter Group中的所有Filter Unit和SSTable中的其他数据都存储在磁盘中,但并不是所有的Filter Unit都是enable的,只有enabled的Filter Unit才会被用于执行key-existence检查。
LRU队列中的每个元素都与一个SSTable关联,并记录了该SSTable的元数据,其中就包含其驻于内存中的enabled filter units。$Q_i$管理enabled filter unit的数量为$i$的SSTable,例如$Q_2$中的每个SSTable都有两个enabled filter unit。
为了确定哪个filter unit应该被disable并将其移出内存,本文采用了一个「expiring」策略。该策略将MQ中的每个item都与一个名为expiredTime的变量关联,该变量表示相应的SSTable应该变为expired,并需要选择一个SSTable来调整其BF的时间点。
具体来讲,$expiredTime = currentTime + lifeTime$,其中$currentTime$表示到目前为止KV Store的$Get$请求总数,$lifeTime$是一个固定值(实践表明ElasticBF对其取值并不敏感)。
根据以上定义,当一个SSTable被插入到一个队列时,其$expiredTime$被初始化为$currentTime+lifeTime$。并且,每当读到该SSTable时,其$expiredTime$值都会根据当前的$currentTime$值进行更新。
当$currentTime$大于某个SSTable的$expiredTime$时,其被标记为expired,这意味在其$liftTime$期间未被访问,此时该SSTable被视为Cold-SSTable,并且将会disable它的部分Filter Unit。
对于每次访问,我们根据原始的MQ算法来寻找「expired」SStable。为了避免「expired」SSTabkle仍然有大量的enabled filter unit,我们将会垂直按照$Q_m$到$Q_1$,水平按照从LRU到MRU的顺序来查找「expired」 SSTable。当找到一个「expired」SSTable后将会disable它的一个Filter Unit,并将其移到下一层的队列中。重复以上步骤,直到找到足够的内存空间来将Hot-SSTable的Filter Unit加载到内存。若是找不到足够的内存空间则跳过此次调整。