
SpanDB: A Fast, Cost-Effective LSM-tree Based KV Store on Hybrid Storage
Background
- 基于LSM-Tree的KV-Store 正变的越来越受欢迎和重要
- 主要用于在企业服务中存储半结构化数据(例如:Google的LevelDB,Facebook的RocksDB);
- 一些分布式数据库的存储引擎也使用了KV-Store(例如:Ceph,MyRocks,TiDB,Cassandra);
- 最新出现了一些高速商用NVMe SSD,其超低延迟和高带宽的优势,为推动新的KV-Store的设计提供了机会;
- ==但是当前基于LSM-Tree的KV-Store并未能完全发挥NVMe设备的潜力==:
- 在50%写负载的情况下,在Optane PX4800X上部署的RocksDB与SATA SSD相比吞吐仅仅提高了23.58%;
- 常见的KV-Store设计的IO路径未能充分利用低延迟的NVMe SSD,尤其是对于一些较小的写操作。这对于写WAL尤为不利,WAL位于写操作的关键路径上,容易成为性能瓶颈。
Challenge
Challenge 1:Fast Accesses to Fast Devices
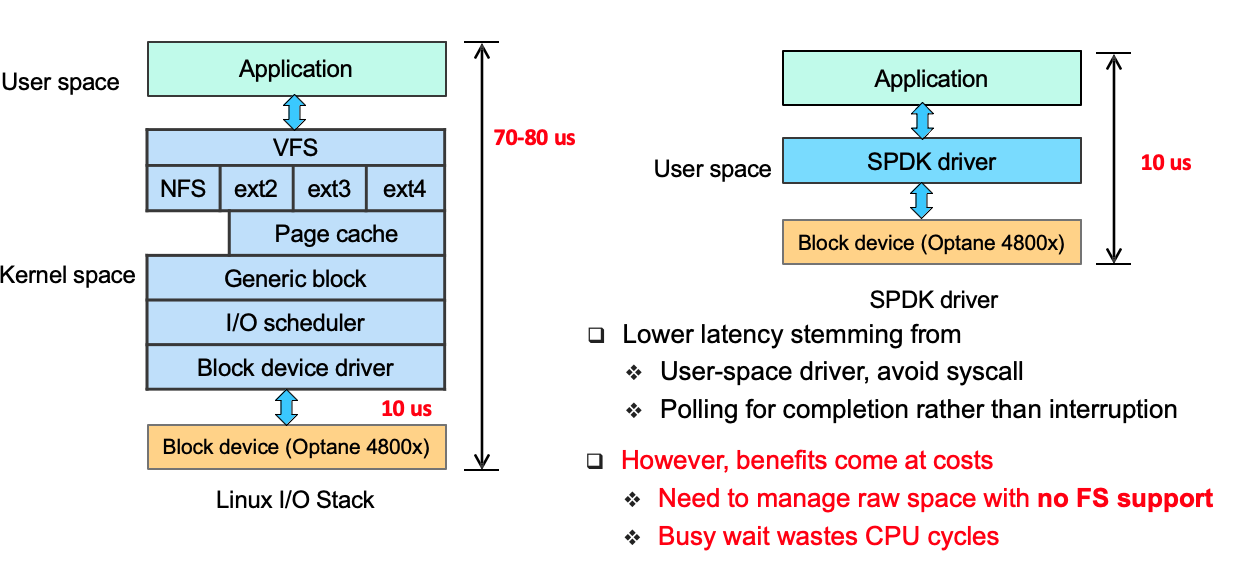
第一个挑战是如何做到快速访问这些快速存储设备。
现在虽然有使用NVMe SSD的KV-Store,但是并没有能充分利用其低延迟和高带宽,其中一个原因就是:操作系统的I/O栈严重拖垮了NVMe SSD的性能。
考虑到Linux内核I/O栈开销在总I/O延迟中不再是可以忽略的,Intel 开发了 SPDK,SPDK是一组用于访问高速 NVMe 设备的用户态库。SPDK 把驱动移动到了用户空间,避免了系统调用并支持了零拷贝访问。它轮询硬件完成,而不是使用中断,并避免I/O路径中的锁。
通过使用SPDK(Storage Performance Development Kit)绕过文件系统和Linux I/O stack来直接访问NVMe SSD设备,则能充分发挥NVMe SSD设备的性能优势。通过使用SPDK来直接访问块设备,可以做到:
- 将存储用到的驱动转移到用户态,避免系统调用
- 使用轮询硬件,而不是中断(中断模式带来了不稳定的性能和延时的提升)
这样所带来的代价是:
- 需要在没有文件系统支持的情况下管理裸设备的存储空间;
- 『忙等待』会浪费GPU周期(新的NVMe接口附带了访问约束,例如要求绑定整个设备以进行SPDK访问,或者建议将线程固定在core上);
注 1:考虑到Linux内核I/O栈开销在总I/O延迟中不再是可以忽略的,Intel 开发了 SPDK,一组用户态的库/工具来访问高速的 NVMe 设备。SPDK 把驱动移动到了用户空间,避免了系统调用并支持了零拷贝访问。它轮询硬件完成,而不是使用中断,并避免I/O路径中的锁。
注 2:『忙等待』是指指在单CPU情况下,一个进程进入临界区之后,其他进程因无法满足竞争条件而循环探测竞争条件。其缺点是,在单CPU情况下,等待进程循环探测竞争条件,浪费了时间片。
Challenge 2:Thread Sync Overhead in Group Logging
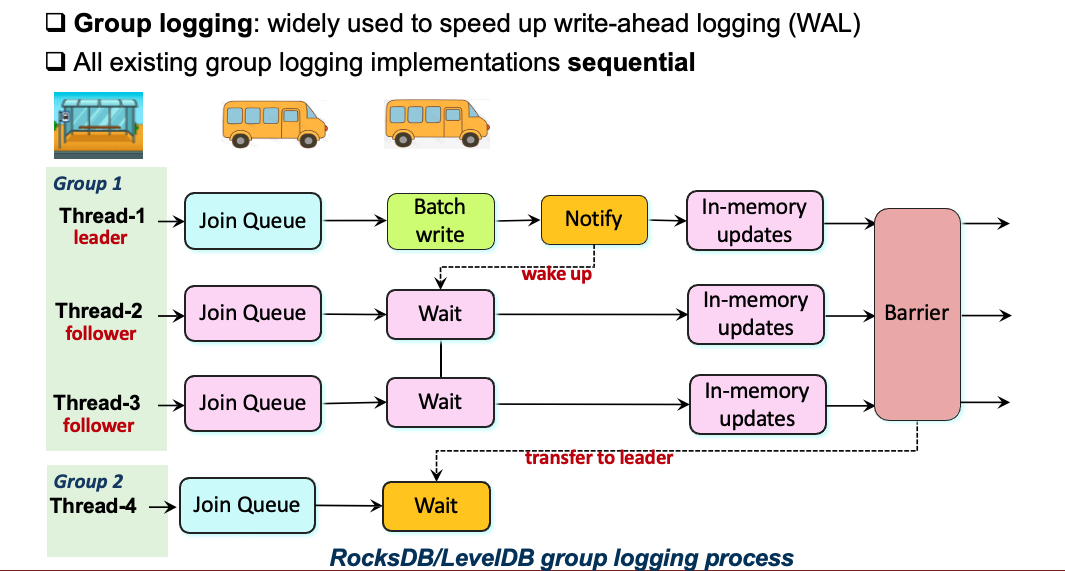
第二个挑战是Group Logging的线程同步开销。
当前基于LSM-Tree的KV-Store多采用Group Logging来加速写WAL,Group Logging机制采用线程同步顺序写的实现方式。步骤如下:
- 当已经有一个正在进行中的写操作时(已经有一个Group在写WAL),处理写请求的 workers 线程通过加入一个共享队列组成一个新的组,第一个进入队列的线程被指定为组的 leader;
- leader 从所在Group的其他写线程中收集日志项,直到前一个组的 leader (刚刚完成写入)通知它可以开始写WAL。此时将关闭当前组的大门,随后到达的线程将启动一个新的组;
- leader将收集到的日志项批量写入到WAL,然后唤醒当前Group中的其他线程,此时Group中的所有线程可以并发写Memtable来执行内存更新(跳表支持无锁并发);
- 最后同步等待Group中所有线程完成内存更新,然后唤醒下一个Group的leader线程;
这种设计存在两个问题:
- 单个leader线程的顺序logging操作不能充分利用SSD的带宽;
- 线程的同步开销过大,Optane SSD的WAL写延迟超过80%;
Related Work
最近也有一些相关的优化工作,但是都存在一些关于兼容性、性能以及成本的问题。
- 基于LSM-tree的KV-Store的优化:PebblesDB [SOSP’17], SILK [ATC’19], ElasticBF [ATC’19], SplinterDB [ATC’20]
- 修改了一些数据结构,但还是采用了传统的Linux I/O栈;
- 基于NVMe SSD的KV-Store:KVSSD [SYSTOR’19], KVell [SOSP’19], FlatStore [ASPLOS’20]
- 硬件成本过高,且在一些情况下没有事务支持;
这篇论文的主要切入点和方法是:
- 成本效益:将『小而快』的设备和『大而慢』的设备结合使用;
- 充分利用快速设备:主要包括延迟、带宽和容量优势;
- 兼容性:没有对数据结构进行修改,能兼容RocksDB的数据文件;
Design: SpanDB
SpanDB Overview
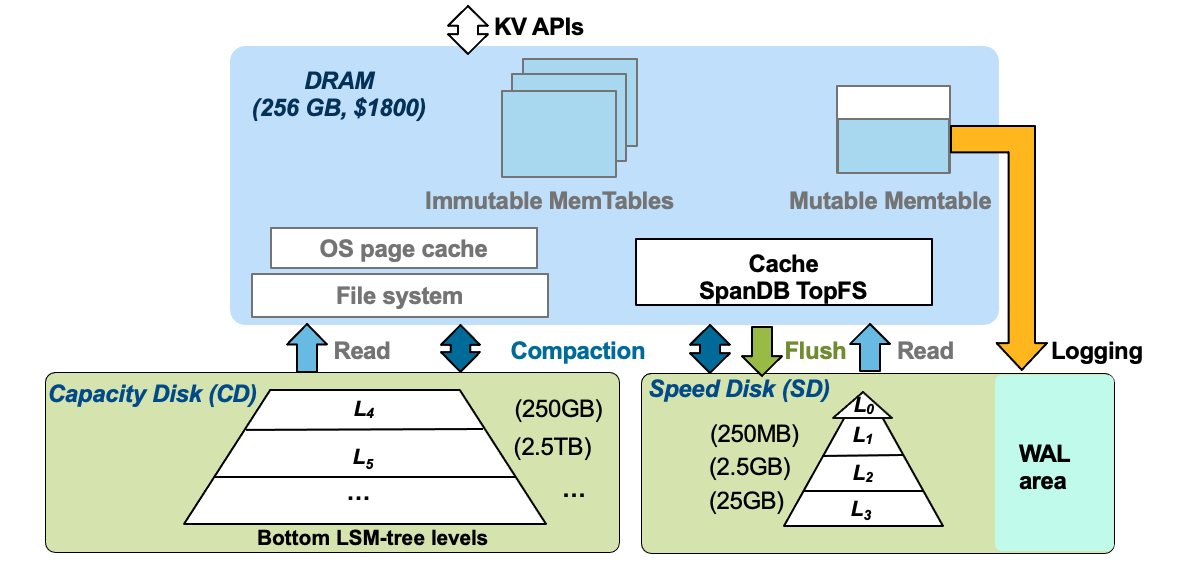
- 首先在 DRAM 中保留了 RocksDB Memtable 的相关设计,使用一个可变memtable和多个不可变memtable。SpanDB 几乎不会对 RocksDB 的 KV 数据结构、算法或者操作语义进行修改。这里的主要区别在于它的异步处理模型,以减少同步开销和自适应调度任务。
- 将磁盘分为SD和CD。SD意为speed disk,即高速磁盘,这里是指NVMe设备。CD意为capacity disk,是低速大容量盘,例如传统机械硬盘。
- SD:SD被进一步划分为WAL区域和LSM Top level区域(数据区域)
- WAL区域:SpanDB 通过 SPDK 将 SD 当作裸设备管理并重新设计了 RocksDB 的 WAL 批量写入,以实现快速、并行的日志记录
- 数据区域:为了最小化 RocksDB 的修改,SpanDB 基于SPDK设计实现了一个轻量级的自带缓存的文件系统 TopFS,该区域接收所有的Flush操作,同时接收LSM-Tree相关层的读操作;
- CD:将LSM-Tree的剩余层放入CD中,这一部分数据大多是冷数据,且数据量大。将这一部分数据放入CD主要是基于成本考虑
- SD:SD被进一步划分为WAL区域和LSM Top level区域(数据区域)
- SpanDB对不同类型的流量进行了区分。
- SD的WAL 区域只进行 log 的操作,SD 的数据区域接受所有 flush 操作。
- 此外,SD 数据区和 CD 都可以容纳用户读和Compaction操作,SpanDB 还执行了额外的优化,以支持在两个分区上同时进行压缩,并自动协调前台/后台任务。
- 最后,SpanDB 能够基于对两个分区的实时带宽监控实现动态调整 LSM-tree level的布局。
- 使用SPDK可以绕过文件系统和Linux I/O stack直接访问NVMe SSD设备来写WAL。SPDK通过引入以下技术,实现高性能存储技术:
- 将存储用到的驱动转移到用户态,避免系统调用
- 支持零拷贝
- 避免在IO链路上使用锁
- 使用轮询硬件,而不是中断,中断模式带来了不稳定的性能,并且增加了延时
Async. KV Request Processing

SpanDB设计了异步的KV请求处理。
在慢速设备的时代,我们通常使用多线程技术,采用远多于CPU核心数的线程数量,尽可能避免慢速设备造成的较长时间的等待。
进入NVMe SSD时代,在SPDK技术加持下,线程同步(比如睡眠和唤醒)很容易花费比 I/O 请求更长的时间。在这种情况下,线程过度配置不仅增加了延迟,还会降低总体资源利用率,从而降低吞吐量。
因此SpanDB采用了异步请求处理。在多核机器上,为每个CPU核分配一个线程,然后将线程分为==客户端线程和SpanDB内部线程,SpanDB内部线程进一步被分为两个角色:loggers线程和workers线程==。
- loggers主要负责写WAL;
- Workers负责后台任务处理(flush/compaction)以及一些非I/O任务,例如Memtables的写入和更新、WAL日志项的准备、事务相关的加锁与同步;
asynchronous read(A_get):
- client线程会首先尝试进行memtable读取,若命中则可直接获取返回结果。
- 若未命中,则将读取请求放入到$Q_{read}$中,随后通过获取请求状态接口获取结果。
- worker线程会随后读取并执行$Q_{read}$中的读请求,并设置读取结果。
asynchronous write(A_put):
- client线程直接将写请求压入$Q_{ProLog}$队列,随后通过获取请求状态接口获取结果。
- worker线程读取$Q_{ProLog}$中的写入请求,序列化得到WAL 数据项并压入到$Q_{log}$。$Q_{ProLog}$队列和$Q_{Log}$队列是设计用于实现batched logging。
- logger线程会一次性读取$Q_{log}$队列中所有的请求,执行group logging,并将写入请求压入到$Q_{EpiLog}$队列。
- worker线程会从$Q_{EpiLog}$线程读取请求,执行最终的memtable更新操作。
Parallel Logging via SPDK

通过SPDK执行并行的Logging操作。
SpanDB配置了多个logger线程并发写入,每个logger有单独的WAL data buffer。
- 为实现并行写入,每个logger通过原子操作分配得到下一个写入位置。
- 每个Logger抓取它在$Q_{log}$队列中看到的所有WAL数据项,并将这些WAL数据项聚合到尽可能少的4KB块中
- 然后通过窃取一个请求的 SPDK 忙等待时间来准备或检查其他请求来执行流水线操作
通过两个专门的Logger就能满足使用Optane作为WAL的写入需要。此外,SpanDB通过分配一个page作为元数据页来在没有文件系统支持的情况下记录/管理元数据信息。
SpanDB在SD的WAL area预先分配若干个逻辑page,每个page有一个唯一的LPN(Log Page Number)。其中一个page作为metadata page。若干个连续的page组成一个log page group,每个group对应一个memtable,容量足够容纳一个memtable的WAL。当memtable flush完成后,log group将会被回收重用。meta data page记录每个log page group的起始LPN。
Dynamic LSM-Tree Level Placement
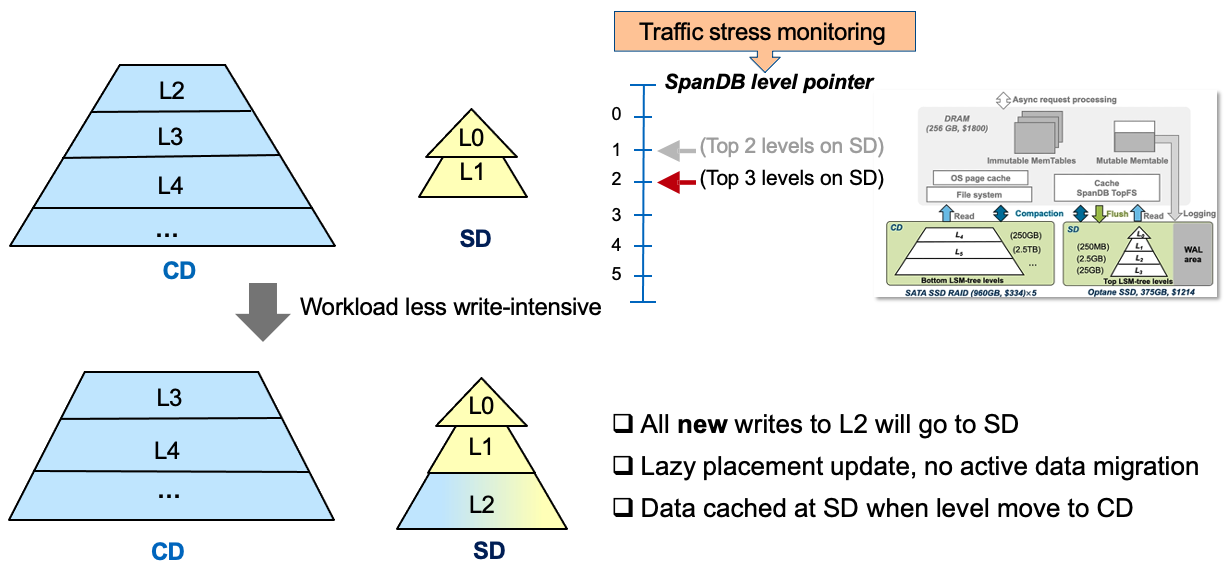
SpanDB 采用了动态分区的方法,它维护了一个 head-server 线程来监视 SD的带宽使用情况,并在其带宽利用率低于$BW_L$时触发SSTable文件重定位,直到达到 $BW_H$ 或 SD 满,其中$BW_H$和$BW_L$是两个可配置的阈值。
这里对SSTable文件进行重定位而不是将文件在SD与CD之间进行搬迁,随着compaction的进行,新创建的文件会被放置到相应的位置。有一个指针来表明该LSM-Tree的哪一层应该放入NVMe,例如:当该指针指向3时,表明top 3层应该放入NVMe。然而,该指针仅仅只是代表新创建的文件的目的位置,有可能出现新创建的L3层的文件在SD,而老的L2层文件在CD。当然这种情况比较少见,因为高层的文件更小,他们会更频繁的被compaction