
Introduction
Amazon的很多服务仅需要通过一个「主键」来访问数据库,因此Dynamo只提供了一个简单的「主键」接口来满足这些服务的需求。
Dynamo综合使用了一些已有的技术来实现可扩展性和可用性:
- 数据通过「一致性哈希」进行分区和复制;
- 通过将「对象」进行版本化来促进一致性;
- 在更新过程中,通过一种类似Quorum的技术和一个分布式副本同步协议来维护副本之间的一致性;
- Dynamo使用了一种基于Gossip的分布式故障检测和成员协议;
Dynamo是一个完全分布式的系统,极少需要人工干预。在Dynamo中添加和删除节点时不需要手动分区和再分配。
Background
传统的生产系统通常将它们的数据存储在关系数据库中。然而,对于许多更常见的数据持久性使用模式来说,关系数据库并不是一个理想的解决方案。这些服务中的大多数只通过「主键」存储和检索数据,不需要RDBMS提供的复杂查询和管理功能。这些多余的功能往往需要昂贵的硬件和熟练的操作人员,这使其成为一种非常低效的解决方案。
商业系统中使用的数据复制算法通常采用「同步协调复制」,以提供强一致性的数据访问接口。为了实现这个级别的一致性,这些算法必须对一些故障场景下的可用性进行权衡。
从很早的数据库复制工作中可以知道,在可能出现网络故障时,无法同时实现「强一致性」和「高可用性」。
Dynamo被设计为提供最终一致性的数据库,也就是说所有的更新最终都会到达所有的副本节点。
一个重要的设计考虑因素时什么时候去解决「更新冲突」,例如:冲突可以在读或写操作时执行更新。很多传统的数据库在执行写入操作时解决冲突,尽量降低读操作的复杂性。在这种情况下,如果写请求的数据无法在规定的时间内到达所有副本节点,则写请求可能会被拒绝。另一方面,Dynamo的设计目标是实现一个总是可写的数据库(「always writeable」),也就是说数据库对于写操作来说是高可用的。
另一个设计选择是由谁来执行「冲突解决」,数据库和用户应用程序都可以用来执行「冲突解决」。如果冲突解决是由数据库来完成,那么它能选择的处理方式就非常受限,在这种情况下,数据库只能使用简单的策略来解决更新冲突(例如「最后写者获胜」,也即「last write wins」)。另一方面,由于用户应用程序了解数据模式,它可以决定最适合客户体验的冲突解决方案。
Dynamo的一些其他设计原则包括:
- 增量可伸缩性:Dynamo必须支持扩展存储节点,并且对系统操作人员和系统本身的影响最小。
- 对称性:Dynamo中的每个节点具有完全相同的职责,不应该有一个或多个承担特殊角色或额外职责的节点,这种对称性设计能简化系统配置和维护的过程。
- 去中心化:去中心化是对称性设计的延伸,设计应该更倾向于去中心化的「点对点技术」,而不是「集中控制」(经验表明,集中控制会容易导致服务中断)。
- 异构性:系统需要能够利用其基础设施中的异构性(节点之间的异构性),例如:工作分配必须与单个服务器的能力成正比。
Dynamo的目标需求包括:
- 首先,Dynamo的目标用户是那些需要「总是可写」的数据库的用户应用程序,更新操作并不会因为故障或并发写入而被拒绝;
- 其次,Dynamo是为单个管理域中的基础设施构建的,这假定所有节点都是可信的;
- 第三,使用Dynamo的用户应用不要求支持层次命名空间或复杂的关系模式;
- 第四,Dynamo是为需要至少99.9%的读写操作在几百毫秒内执行的对延迟非常敏感的应用程序所构建的。为了满足这些严格的延迟要求,必须避免通过多个节点路由读写请求(Dynamo可以被描述为0跳DHT,也即「Zero-Hop Distributed Hash Table」,其中每个节点在本地维护足够多的路由信息,以便将请求直接路由到适当的节点);
System Architectures
Dynamo使用到的主要技术,以及它们的优势:

System interface
Dynamo公开了两个简单的接口来执行数据的存取:put()和get() 。
get(key)操作在数据库中查找与该key相关的对象副本,返回单个对象或者存在冲突的对象列表(这是因为Dynamo将冲突处理交给了用户应用程序,所以需要将所有的冲突对象都返回给用户);put(key, context, object)操作根据对应的key决定对象副本放置位置,并将副本写入磁盘。
Dynamo将调用方提供的键和对象都视为不透明的字节数组,使用MD5算法对Key进行加密操作,得到一个128位的标识,然后根据此标识来选择节点进行存储。
Partitioning Algorithm
Dynamo的分区方案依赖于「一致性哈希」来跨节点分配负载。
在「一致性哈希」算法中,哈希函数的输出范围被视为一个固定的圆形空间或「环」。系统中的每个节点在这个空间内被分配以一个随机值,代表它在环中的「位置」。对数据项的Key进行哈希计算可以得到在环中的一个位置,从这个位置沿顺时针方向找到的第一个节点就是负责存储该数据项的节点。因此,每个节点负责存储环中一个区域的数据,也就是在环中当前节点和其前驱节点之间的区域中的数据。
这种设计的优点是,一个节点的加入或离开只影响它的相邻节点,其他节点不受影响。
基本的一致性哈希算法存在两个挑战:
- 首先,环中 每个节点的位置分配是随机的,这可能会导致数据和负载分布不均衡;
- 此外,该算法没有考虑节点的异构性(不同节点的性能可能不同);
为了解决以上问题,Dynamo使用了一致性哈希算法的变体:每个节点被分配到环中的多个位置(也称为分配了多个Token),一个节点被划分为多个「虚拟节点」。
加入虚拟节点的优点包括:
- 当某个节点不可用时,由该节点处理的负载将会被均匀的分布到其他可用节点上;
- 当一个节点再次可用,或者新加入一个节点时,该节点可从其他可用节点接收大致相同的负载;
- 可以根据节点的性能(异构性)为其分配虚拟节点的数量;
Replication
为了实现高可用性和持久性,Dynamo将其数据复制到多个主机上。每个数据项复制到N个主机上,其中N是一个通过「per- instance」配置的参数。
对于每一个键K,首先通过一致性哈希将其分配给一个「协调者节点」(coordinator node)。协调者节点负责复制落到其负责范围内的数据项。协调者节点除了将其负责范围内的数据项存储到本地以外,还在环中其顺时针方向的N-1个节点中复制存储这些数据项,由此完成多副本存储。
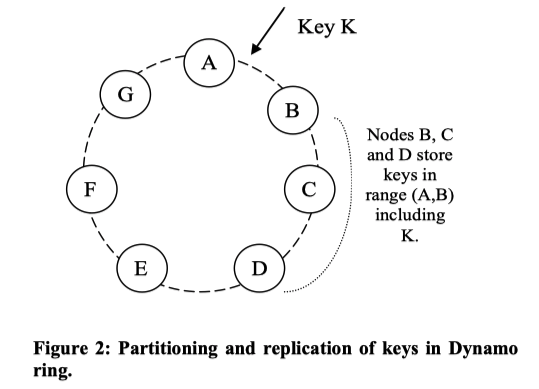
如图2所示,节点B除了将键K存储到本地,还将其复制存储到节点C、D中。也就是说,节点D不光要存储范围(C, D)内的数据项(作为这个范围的协调者节点),还要存储范围(A, B)和范围(B, C)内的数据项(作为这两个范围的备份副本节点)。
负责存储特定Key的节点列表被称为「偏好列表」或「首选项列表」(Preference List)。需要注意的是,由于使用了虚拟节点,所以存储特定Key的N个节点可能并不是来自N个不同的物理节点。为了解决这个问题,可以通过跳过环中的一些位置来构造键的「首选项列表」,以确保该列表中的节点都来自不同的物理节点。
Data Versioning
Dynamo提供最终一致性,允许更新操作异步传播到所有副本节点。
Dynamo将每次修改的结果视为数据的一个新的、不可变的版本。系统允许一个对象的多个版本存在。大多数时候,新版本包含了以前的版本,系统本身可以确定权威版本。
但是当发生故障并进行并发更新时,可能会出现版本分支,导致对象的版本冲突。在这种情况下,系统本身无法协调同一对象的多个版本分支,必须交由用户来执行版本分支的协调合并。
Dynamo使用向量时钟来捕捉同一对象的不同版本之间的因果关系。向量时钟是一个<node, counter>对,可以通过检查向量时钟来判断一个对象的两个版本是在同一分支上存在因果顺序,还是在不同的分支上无因果顺序。如果两个版本的counter相同,则说明这两个版本没有因果顺序,发生了分支。
在Dynamo中,当客户端希望更新一个对象时,它必须指定更新的是哪个版本。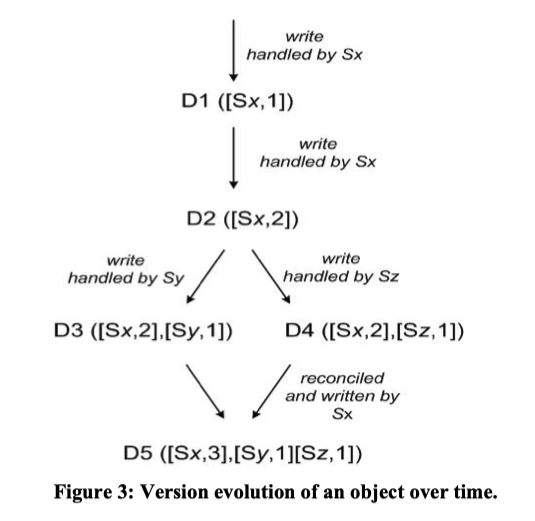
- 如图3所示,客户端写入了一个新的对象,负责处理这个写操作的节点为Sx,其生成的向量时钟为
[Sx,1],系统现在有对象D1和它对应的向量时钟([Sx, 1])。 - 该客户端继续更新该对象,还是节点Sx处理该操作请求,生成向量时钟
[Sx, 2],系统现在有对象D2和它对应的向量时钟([Sx, 2]),对象D2由对象D1衍生而来,对象D2覆盖了对象D1 。但是可能会有D1的副本仍然存在于尚未见过D2的节点上(异步更新,最终一致性)。 - 该客户端再次更新对象,此时是另一个节点Sy处理该操作请求,生成新对象D3和对应的向量时钟
([Sx, 2], [Sy, 1])。 - 接下来假设另一个客户端读取D2,然后尝试对它更新,由另一个节点Sz执行操作请求,生成对象D4和对应的向量时钟
([Sx, 2], [Sz, 1])。 - 已经知道D1或D2的节点在接收到D4及其向量时钟后可以确定D1和D2被新数据D4覆盖,D1和D2可以被垃圾回收;但是知道D3的节点在收到对象D4后,发现这两个对象之间没有因果关系。此时,当客户端进行读取时,这两个对象版本必须都响应给客户端,由客户端进行冲突处理,协调后生成的对象为D5,其向量时钟为
([Sx, 3], [Sy, 1], [Sz, 1])。
Execution of get() and put() operations
Dynamo中的任何存储节点都可以接受客户端对任意键的get()和put()操作。
客户端可以通过两种方式来选择节点:
- 通过一个通用的负载均衡器根据负载信息来路由其请求信息,其优点是客户端不需要链接任何额外代码;
- 通过一个可以感知分区信息的客户端库来将请求直接路由到适当的协调节点(Coordinator Nodes),其优点是可以实现更低的延迟,因为这跳过了潜在的路由请求转发;
处理读写请求的节点被称为协调者(Coordinator),通常这是「Preference List」中前N个节点的第一个节点。如果通过负载均衡器接受请求,访问key的请求可能会被路由到环中的任何随机节点。在此情况下,如果接受请求的节点不在被请求键的「Preference List」的前N位,那么该节点将不会对此请求进行协调,而是将请求转发给「Preference List」中前N个节点中的第一个节点。
读写操作涉及「Preference List」中的前N个健康节点,这会跳过那些宕机或不可访问的节点。
为了维护副本之间的一致性,Dynamo使用了类似于Quorum System中的一致性协议。该协议有两个可配置参数:
- R:成功读取的最小节点数;
- W:成功写入的最小节点数;
设置R和W使其满足R + W > N,得到一个类Quorum的系统(此时R和W有交集,必定有一个节点同时完成了写入和读取)。在此模型下,操作延迟由最慢的R或W副本决定。
当收到一个put()请求时,协调者生成一个新的版本和对应的向量时钟,并将新的版本写到本地。然后,协调者将新的版本发送给其他副本节点,只有当至少W-1个节点响应写入成功时,该put()操作才被认为是成功的。
Handling Failures: Hinted Handoff
暗示切换:如果节点A在写操作期间出现故障无法访问,那么本应存储在A上的副本将会被发送给节点D。
这样做的目的是为了保障持久性和可用性。
发送到D的副本会在元数据中保留一个「提示」,提示该副本原来应该发送给哪个节点,在这里原来应该发送给节点A。
当一个节点收到一个带有「提示」的副本时,该节点会将收到的相关副本数据保存储在一个单独的本地数据库中,定期扫描。当检测到节点A已经恢复正常时,节点D会尝试将该副本数据发送给节点A,发送成功后,节点D会在不减少系统中副本总数的前提下从本地存储中删除相关数据。
通过「暗示切换」,Dynamo确保读写操作不会因为临时的节点或网络故障而失败。
Handling permanent failures: Replica synchronization
Dynamo通过一个「反熵协议」来保持副本的同步。
Dynamo通过Merkle树来快速检测副本之间的不一致,并最小化需要传输的数据量。
每个物理节点为每个Key Range维护一个单独的Merkle树(每个物理节点分为多个虚拟节点,每个虚拟节点保存一个Key Range的数据)。
两个节点通过交换Merkle根来检查数据是否一致。这种方案的缺点是,当有节点加入或离开时,节点的Key Range会发生变化,Merkle树也需要重新计算。
Membership and Failure Detection
在Amazon环境中,节点中断(由于故障和维护任务)通常是短暂的,但可能会持续较长时间。节点中断很少会表示为永久中断,因此不应该导致分区分配的再平衡和不可访问副本的修复。
因此,更恰当的方法是通过显式的方式向Dynamo环中添加或删除节点。
管理员可以通过命令行工具或浏览器连接到Dynamo节点,并发出成员关系修改,以将节点加入环中或从环中删除节点。服务该请求的节点会将「成员关系更改」和「更改发生时间」写入到其持久存储中。成员关系更改会形成一个历史记录,因为一个节点可以被多次删除或添加。
Dynamo通过一个基于Gossip的协议传播成员关系更改,并最终达成一致的成员关系视图。每个节点每秒钟联系一个随机选择的节点,两个节点会有效的协调它们持久化存储中的「成员关系更改历史」。
当一个节点第一次启动时,它会选择它的「Token Set」(令牌集,也就是一致性哈希空间中的虚拟节点集),并将节点映射到它们自己的令牌集。映射持久化到磁盘上,并且最初只包含本地节点和令牌集。存储在不同节点中的映射关系在协调成员关系更改历史时得到协调。
因此,分区和放置信息也基于Gossip的协议传播,并且每个节点都知道所有「对等节点」(peers)处理的令牌范围。这允许每个节点将Key的读写操作直接转发给其右边的节点集。
上述加入节点的机制有可能会产生一个临时的逻辑分区。例如,管理员联系节点A将其加入环中,然后再联系节点B将其加入环中。在这种情况下,节点A和B都认为自己是环中的成员,但它们都不会立刻意识到对方的存在。
为了防止逻辑分区,一些Dynamo节点担任「种子」的角色。「种子」是通过外部机制发现的节点,所有节点都知道这些节点。因为所有的节点最终都需要与「种子」节点进行成员关系的协调,所以不太可能会出现逻辑分区。
「种子」节点集可以从静态配置中获得,也可以从配置服务中获得,典型的「种子」节点是Dynamo环中功能完整的节点。
Adding/Removing Storage Nodes
当一个新的节点(比如X)被添加到系统中时,它会被分配一些令牌,这些令牌随机分布在环中。
对于分配给节点X的Key Range,可能当前已经有一些节点(小于等于N个节点)在负责这些Key Range。因为此时已经将这些Key Range分配给了节点X,所有此前负责这些Key Range的一些节点不再负责对其处理,这些节点将会把这些Key Range内的键转移给节点X。
例如,当一个节点X被加入到图2中的A与B节点之间时,它所负责的Key Range是[(F,G), (G, A), (A,X)]。因此,节点B、C和D不再需要存储对应Key Range 范围内的键,并将在得到节点X的确认后把对应的键传输给节点X。
当一个节点从系统中删除时,键的重新分配将以相反的过程进行。
Implementation
Dynamo中,每个存储节点由三个软件组件组成:请求协调组件、成员关系和故障检测组件,以及一个本地持久化引擎组件。
Dynamo的本地持久化组件允许使用不同的存储引擎,以满足不同应用的访问模式。
如果某个节点响应了一个旧版本对象,协调节点将会对这些节点的旧版本对象进行更新,这个过程被称为「读时修复」(read repair)。