Learned Index
前言
在数据库中,索引用于实现数据的快速访问检索,得到数据的存在信息:是否存在、存在的位置。
通过机器学习能够学习到数据库中数据的「分布特征」,从而根据此特征动态建立起专用的索引方式。
The Case For Learned Index Structures(SIGMOD-2018)
文章信息
主要作者及单位
- Tim Kraska (MIT)
- Jeff Dean (Google)
会议/期刊
- SIGMOD-2018
内容
简介
本文提出了「Learned Index」的基本概念和构建思路,并提供了替换传统索引方案的一些案例和优化方法,是「Learned Index」的开山之作。
索引是模型的一种:
- 「Range Index」索引:以B-Tree为代表的Range Index索引可以看作是一个从给定Key到一个「排序数组」的Position的预测过程;
- 「Point Index」索引:以Hash为代表的Point Index索引可以看作是从给定Key到一个「未排序数组」的Position的预测过程;
- 「Existence Index」索引:以Bloom Filter为代表的Existence Index索引可以看作是一个预测给定Key是否存在的过程;
索引系统是可以替换的,可以用机器学习模型替换现有的索引模块来优化检索性能。
且上述的索引结构是一种通用的数据结构,没有对数据分布做任何假设,也没有利用现实世界数据中更常见的模式。而描述数据分布的连续函数可以用来构建更有效的数据结构或算法。
用机器学习模型去做索引可能存在的问题:
- 语义保证:通过数据训练得到的机器学习模型是存在误差的,而数据库中的索引经常需要满足严格的限制条件。
- 训练问题:如何避免过拟合,当数据更新、插入和删除后,数据分布会发生变化,变化后的重新训练。
- 开销问题:训练开销和计算开销。
Range Index - 代替B树
数据库系统通常使用B-Tree或B+-Tree来实现Range Index。查询时给定一个key,B-Tree能索引到包含该key对应范围的叶子节点。
从机器学习的角度来看,可以把B-Tree看作一个「Regression Tree」,B-Tree的建立过程也是依赖数据的,不过它不是通过「梯度下降」的训练方式得到的,而是通过预先定义的规则得到的。
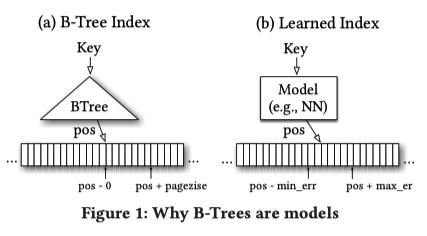
- 如图1(b)所示,对于输入的Key,模型预测得到一个pos,若区间[pos-min_err, pos+max_err]中包含这个KV项,则预测准确,其中min_err的期望值为0,此时预测得到的pos就是KV项的位置;max_err的期望值时pagesize,此时KV项的位置在pos + pagesize。
- 查找过程:通过机器学习模型的预测得到一个查找区间[pos-min_err, pos+max_err],其中min_err和max_err分别是机器学习模型在训练数据上的最小误差和最大误差。然后在此区间上执行二分查找,此时已经将复杂度降低到了一个常数级别。
存在的问题:
Tensorflow的效率问题;- 模型的预测误差问题;
解决方法:
- Learning Index Framework(LIF):LIF针对给定的模型规则生成索引配置,优化并自动进行测试。它采用
Tensorflow自带的神经网络模型去学习简单的函数,然后在真正应用时再生成基于C++的高效索引结构,可以将模型预测优化到30ns以内。 - Recursive Model Index(RMI):RMI主要用来解决模型的「最后一公里」准确度问题。RMI用一个模型树通过层层的模型来不断缩小数据的查找范围,直至叶节点可以拟合最小范围的数据分布。根节点往往采用简单的神经网络模型,其他节点使用线性回归模型,如果数据分布过于复杂而无法拟合,叶子可以直接换成B-Tree结构。
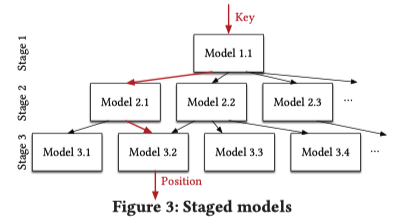
Point Index - 代替哈希
Hash-Map通过使用哈希函数来决定将Key映射到比特数组中的位置。这里的主要挑战在于哈希碰撞问题,也即不同的Key映射到的比特位会有重叠。
常见的哈希碰撞解决方法有:邻接链表法、二级探测等。
而机器学习模型提供了减少哈希冲突数量的替代方案。虽然将机器学习模型作为哈希函数使用的方法并不新鲜,但现有的技术并没有利用底层的数据分布。
Existence Index - 代替Bloom Filter
使用机器学习模型来代替Bloom Filter有两种思路:
- 仅使用机器学习模型来代替Bloom Filter中的哈希函数,来减少哈希冲突;
- 直接用一个二分类机器学习模型来代替Bloom Filter去判断数据是否存在;

总结
基于静态RMI的学习式索引为通过机器学习的方式利用底层数据的分布规律来优化数据库的索引检索性能开辟了新的研究方向。
但静态的RMI仅支持「只读」工作负载,当有插入、更新或删除操作时,数据分布会发生变化,不光RMI的叶节点模型需要重新训练,连接相关叶节点的上层节点也都需要重新训练,大大增加了训练成本。
ALEX:An Updatable Adaptive Learned Index(SIGMOD-2020)
文章信息
主要作者及单位
- Chi Wang (Microsoft Research)
- Tim Kraska(MIT)
会议/期刊
- SIGMOD-2020
内容
简介
论文《The Case For Learned Index Structures》只支持read-only的工作负载,这使得Learned Index不可用于更常见的读写混合负载。
该文的工作ALEX使得Learned Index也支持更新和插入,其核心解决思路为:
- 每个模型管理自己的数据,该部分数据发生变化时不影响其他模型;
- 修改底层的数据存储结构,以支持高效的插入和删除操作;
在性能方面:
- 在read-only工作负载下,ALEX比Learned Index提升了2.2倍,索引缩小了15倍;
- 在read-write工作负载下,ALEX比B-Tree提升了4.1倍,索引缩小了2000倍;
- ALEX还超过了机器学习增强的B+-Tree和内存优化的Adaptive Radix Tree;
节点布局
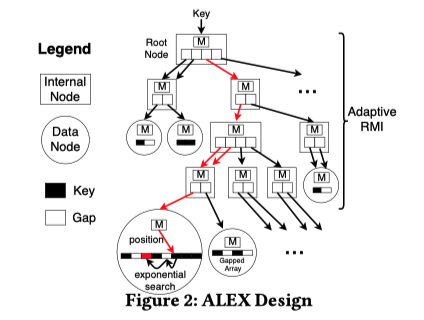
- 数据节点:类似B-Tree,ALEX的每个叶子节点都存储着数据项,因此被称为数据节点(Data Nodes)。如图2圆形节点所示,每个数据节点包含一个线性回归模型,用于将一个Key映射到一个位置,以及两个Gapped Array(数组中间存在间隙,分摊了插入的移动开销,方便插入),分别用于存储Keys和Payloads,Keys和Payloads均为固定大小的,Payloads可以是Records也可以是指向可变大小Records的指针。
- 内部节点:如图2矩形节点所示,作为RMI结构一部分的节点称为内部节点。每个内部节点包含一个线性回归模型以及一个指向子节点的指针数组。内部节点用于提供一种更灵活的方式来划分键空间。
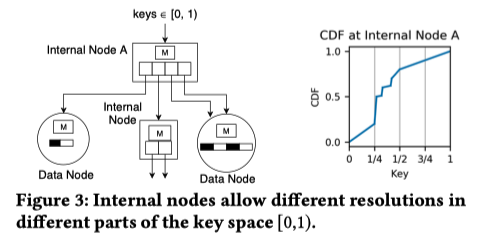
数据查询
- 从根节点开始查询,根据节点模型的计算结果和指针数组来层层选择子节点,直到到达数据节点;
- 到达数据节点后通过其模型来预测要查找的key在key array中的位置,如果需要的话再通过「指数查找」来查找key的实际位置;
- 如果在key array中找到对应的key,则从payloads array数组的相同位置读到value并返回;
数据插入
- 如果在一个未满的数据节点中插入数据:用数据节点中模型的预测位置作为插入位置将新数据插入,如果模型预测的插入位置不能维持有序性则通过「指数查找」来确定正确的插入位置;
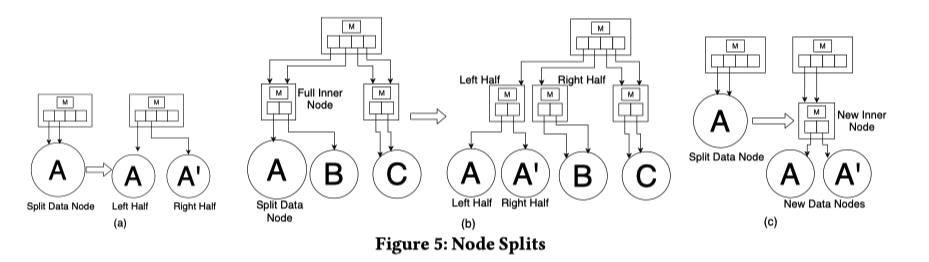
- 如果要插入的数据节点已满:ALEX使用两种机制来创建更多的空间——扩展和拆分。ALEX通过简单的成本模型来确定使用哪种机制。
- 数据节点「满」的判断标准:ALEX并不会等到数据节点完全变满,因为随着间隙的减少Gapped Array的数据移动成本会不断增加。ALEX设置了密度上下限,超过上限就扩展或拆分,低于下限则合并收缩。
数据删除
- 删除操作先找到key的位置,然后从对应的数组中删除key和payload,这并不需要移动数组中的其他key和payload,如果删除导致数据节点的密度小于密度下限则合并收缩;
数据更新
- 数据更新时先查找到key,然后修改对应的payload;
总结
- 通过数据节点和内部节点的划分,构建了动态RMI,从而支持读写混合负载;
- 对数据分布有一定要求,节点均采用的线性回归模型,当难以使用该模型建模时,性能会很差;
RadixSpline: A Single-Pass Learned Index(2020-workshop)
文章信息
主要作者及单位
- Andreas Kipf (MIT)
- Tim Kraska(MIT)
会议/期刊
内容
简介
- 现有的Learned Index实现起来比较复杂,构建速度也比较慢;
- 在这篇文章中,作者指出,一些应用程序的索引不需要单个更新,比如LSM-Tree中的SSTable文件一旦生成便不可修改。且LSM-Tree中的Compaction阶段进行Learned Index构建的最佳时期。Compaction生成的数据是有序的,可以在将其写回磁盘时通过一次遍历完成训练算法。
- 文章提出的Learned Index——RadixSpline(RS)可以通过数据的单次传递完成构建,在索引大小和查找性能方面与RMI相比都比较有竞争力;
- RS只使用了两个超参数(spline error和radix table size),两者都对索引大小和查找延迟有直观和可靠的影响;
结构原理
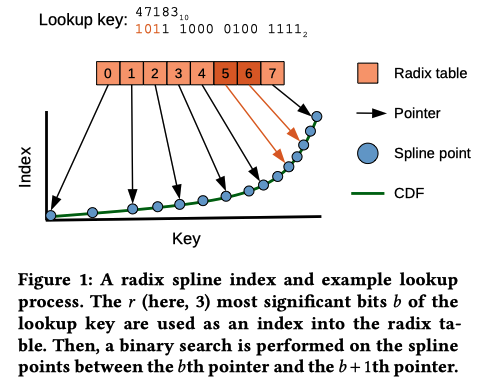
- RS索引用于将lookup key映射到其在底层数据中的位置;
- RS索引由两部分组成:一个「样条点(spline points)」集合和一个「基数(radix)」表。
- 「样条点」是keys的子集,通过样条点,任何lookup key的「样条插值」都将在预设的错误范围内得到预测的查找位置。简单理解样条插值。
- 「基数表」用于根据lookup key快速确定正确的「样条点」,简单来说,基数表通过lookup key的固定长度前缀来限制了可能的样条点的范围(也即通过键前缀范围缩小查找范围)。
- RS根据lookup key的固定长度前缀从「基数表」中找到覆盖该lookup key的两个「样条点」的位置,然后通过「样条插值」来预测lookup key在LSM-Tree中的位置。而且因为「样条插值」是误差有界的,索引查找范围很小。
- 如图1所示前缀长度为3,图中前缀为101,也即十进制5,以此为索引通过「基数表」确定两个「样条点」,然后「样条插值」得到预测位置。
RS构建
Build Spline
- 设数据集索引为$D$,$D_i=(k_i, p_i)$,表示第$i$个数据点,其中$k_i$表示该数据点的key,$p_i$表示该数据点的position;
- 构建「样条模型」S,有$S(k_i) = p_i \pm e$ ,$e$是指定的误差常数,也即模型S预测的位置误差不超过误差常数。该模型通过误差有界的样点插值算法实现,该文使用「GreedySplineCorridor」。
- 对于每个查找key,通过两个最近的「样条点」之间进行「线性插值」产生误差不超过$e$的预测值。
Build Radix Table
「基数表」是一个uint32_t类型的数组,用于将固定长度的key前缀映射到带有该前缀的第一个样条点。构建过程如下:
- 首先根据固定前缀的长度分配适当大小的数组,若固定前缀长度为$r$,则数组的大小为$2^r$;
- 然后遍历所有的「样条点」,每遇到一个新的长度为$r$的前缀$b$,就将有该前缀的样条点偏移量插入到数组偏移量为$b$的位置;
From WiscKey to Bourbon: A Learned Index for Log-Structured Merge Trees(OSDI-2020)
文章信息
主要作者及单位
- Yifan Dai(University of Wisconsin – Madison)
- Remzi H(University of Wisconsin – Madison)
会议/期刊
- OSDI-2020
内容
前言
- Learned Index主要应用于read-only的场景中,而LSM-Tree是为了写优化而设计的,因此将「学习索引」的思想引用到LSM-Tree是个挑战;
- 写操作会破坏数据分布导致需要对Learned Index重新训练,而对于LSM-tree而言,大部分数据是不可修改的,SSTable是只读的,虽然也存在Compaction过程对SSTable进行合并重写。
背景
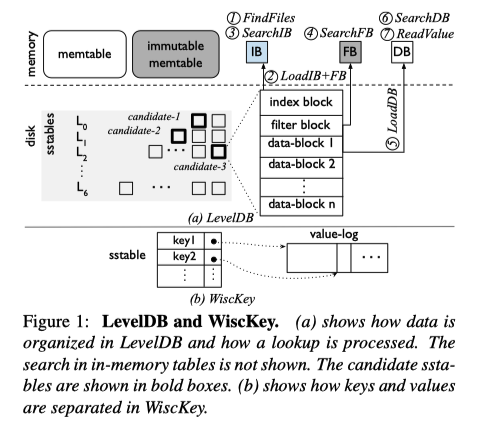
Wisckey和leveldb的公共查询过程:
- FindFiles:找到所有可能包含目标KV项的SSTable
- Load IB + FB:加载备选SSTable的Index Block和Filter Block
- Search IB:查找Index Block(二分查找),得到KV项可能在Data Block中的位置偏移
- Search FB:根据Index Block的查找结果,从Filter Block中选择对应的BF进行查询
- Load DB:如果BF指示存在的话则加载对应的Data Block
- SearchDB:查询Data Block确定KV项的位置
- ReadValue:从Data Block读取Value Log中读取Value的偏移量
Learned Index 是否适合LSM-Tree
上述查询过程可以分为两类:
- indexing部分:在block内部执行查询——Findfiles + Search IB、FB、DB;
- loading部分:将block加载到内存——Load IB、FB、DB;
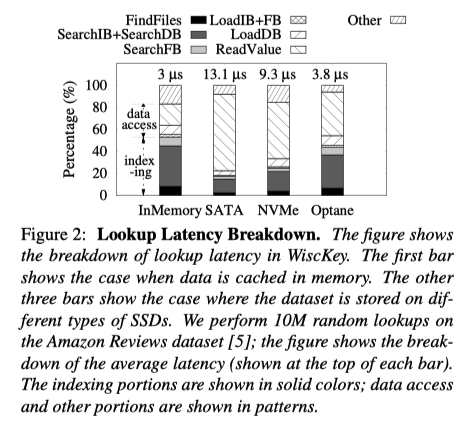
- 随着存储器件读写速度的不断增加,在查询过程中indexing部分延迟所占的比例也不断增加;特别是当数据都缓存在内存中时,indexing的性能就显得尤为重要。
- 而数据缓存在内存中并不会影响Learned Index,此时通过优化indexing部分就能明显提升性能;
文章通过一系列实验得出了以下指导原则:
- 学习深层的SSTable更有优势,深层的SSTable文件生命周期更长;
- 等待SSTable文件的存在时间超过一个阈值之后再对其学习,存在时间超过此阈值的SSTable往往具有更长的生命周期;
- 也不能忽略浅层的SSTable文件,虽然深层的SSTable具有更长的生命周期,但浅层的SSTable文件的访问频率却更高;
- 要根据具体的工作负载特征进行学习;
- 不要学习写工作负载严重的level;
实现