
SILK论文阅读笔记
2023-02-10 10:10:25
# 论文
0x10 长尾延迟
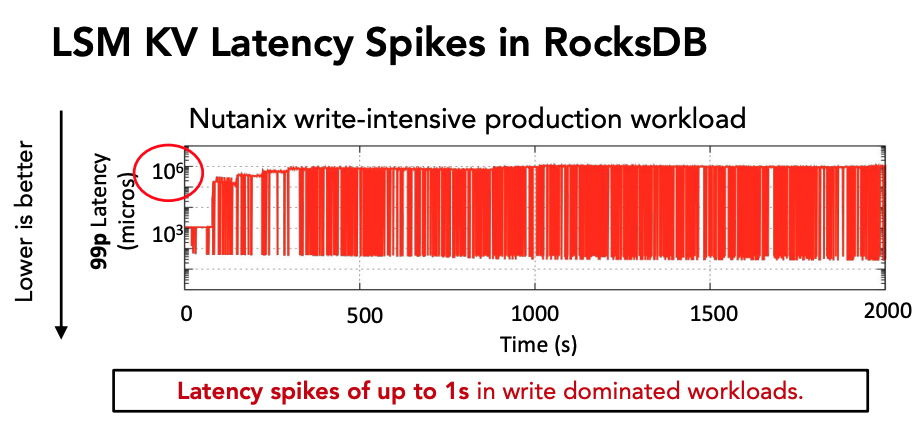
以RocksDB为例,在Nutanix生产环境中的写密集型工作负载下,99%分位的操作尾延迟达到了$10^6$微秒级,也即秒级。
0x20 长尾延迟的原因
出现「长尾延迟」的主要原因是内存中的MemTable写满后无法及时刷新到LSM-Tree中的L0,进而阻塞了「写操作」。
回顾LSM-Tree的写操作流程:
- 首先追加写到WAL中;
- WAL写入成功后再写内存中的MemTable,根据写MemTable的情况返回「写操作」的结果;
- MemTable写满后转为Immutable MemTable;
- 后台线程执行Minor Compaction(也即Flush操作)将Immutable MemTable持久化为磁盘上LSM-Tree中L0的SSTable文件;
- 当L0中的文件数量达到上限或其他Level中的文件大小超过容量上限时执行Major Compaction操作,将本Level的SSTable文件合并写到下一个Level中;
上面的写操作流程中隐含了一些限制写操作的细节,主要包含以下两点:
- 当Compaction操作过于密集时,底层的Compaction操作会和L0-L1的Compaction抢占IO带宽,导致L0中的SSTable文件数量过多,进而阻塞写操作。
- 当Compaction操作过于密集时,底层的Compaction操作还会与Flush操作竞争带宽,导致虽然L0中仍有空间可用,但是Flush操作过慢会导致已满的MemTable无法及时落盘,从而阻塞用户的写操作。
- 此外,Compaction操作还会和WAL竞争IO带宽,从而限制用户的写操作;

0x30 SILK是怎么做的
0x31 经验教训
SILK通过一系列实验得到了以下经验:
- 高延迟的直接原因是MemTable写满后阻塞了用户写操作。间接原因一是因为磁盘中的L0满了导致写满了的MemTable无法落盘到L0中;二是因为并发的大量Compaction操作之间会竞争带宽,导致Flush操作的可用带宽降低,影响了MemTable的落盘速度。
- 通过简单的限制internal operations(Flush和Compaction操作)的带宽并不能解决问题,这种简单粗暴的方法并没有区分Flush、L0-L1 Compaction以及其他Compaction操作的区别,因为这些操作对于用户的操作具有不同的影响,有的起积极作用,而有的起消极作用。
- 现有的一些提高吞吐量的方法仅仅在短期内避免了延迟的峰值,但在长期内加剧了问题,因为这往往增加了在后期的某个时间点同时进行更密集的Compaction操作的可能性。
0x32 SILK设计原则
- 根据负载的变化对internal operation动态分配带宽。这是利用了在实际的生产工作负载中,客户端操作负载往往会随着时间的推移而变化。根据此特点,SILK在用户负载的高峰期为用户操作分配更多的IO带宽,而在用户负载的空窗期将IO带宽分配给Internal Operations。这有两个好处:
- 其一,在用户操作负载的高峰期能避免内部操作和用户操作竞争IO带宽;
- 其二,在用户操作负载的空窗期集中带宽处理内部操作,能避免积累大量的内部操作负载;
- 为LSM-Tree中的内部操作划分优先级。SILK根据内部操作对客户端延迟的影响将其分为三个优先级:
- Flush操作具有最高的优先级,保证内存中有足够的空间能吸收客户端的写操作;
- L0-L1的Compaction操作具有次优先级,保证L0中始终有足够的空间,进而保证MemTable写满后能及时Flush到L0;
- L1以下的Compaction操作具有最低的优先级,因为尽管它们用于维护LSM-Tree的结构,但它们的是否及时执行在短时间内并不会显著影响客户端的操作延迟;
- SILK实现了新的Compaction算法,保证低Level的内部操作能够抢占高Level的内部操作的资源而优先执行。
SILK实现
动态分配IO带宽
SILK使用一个单独的线程来持续监控客户端操作占用的带宽,并将剩余可用的IO带宽分配给内部操作(Internal Operations)。
若LSM-Tree KV Store的总可用带宽为$T$ B/s,SILK测量得到客户端请求所使用的带宽为$C$ B/s,SILK将实时调整内部操作的可用带宽为 $I = T - C - \varepsilon$B/s,其中$\varepsilon$是一个小的缓冲区。
为了调整IO带宽,SILK使用了标准的速率限制器。此外,SILK为Flush和L0-L1的Compaction操作维护了一个最小的可配置的IO带宽阈值,因为这两个操作会直接影响客户端的延迟。
优先级划分和内部操作抢占
SILk维护了两个内部工作「线程池」:
- 一个高优先级的线程池用于执行Flush操作;
- 一个低优先级的线程池用于执行Compaction操作;
部分细节如下:
- Flush操作在内部操作中具有最高的优先级,Flush操作有专用的线程池,并且始终能访问内部操作可用的IO带宽资源。
- 如果有L0-L1的Compaction需要执行,而Compaction线程库中的所有线程都在执行高层的Compaction,则随机选择一个线程暂停原来的Compaction操作转而执行L0-L1的Compaction操作。必要时,为了保证L0-L1 Compaction的执行,需要将其移动到高优先级线程池中执行,也即具有和Flush相同的优先级。
- 高Level的Compaction操作可能会被抢占,可能被L0-L1的Compaction抢占,在用户负载增加时整个Compaction线程的IO资源可能也会被抢占,导致高Level的Compaction操作暂时停止执行。